Nodes Browser
ComfyDeploy: How ComfyUI-OmniGen works in ComfyUI?
What is ComfyUI-OmniGen?
ComfyUI custom node implementation of OmniGen
How to install it in ComfyDeploy?
Head over to the machine page
- Click on the "Create a new machine" button
- Select the
Editbuild steps - Add a new step -> Custom Node
- Search for
ComfyUI-OmniGenand select it - Close the build step dialig and then click on the "Save" button to rebuild the machine
ComfyUI-OmniGen
A ComfyUI custom node implementation of OmniGen, a powerful all in one text-to-image generation and editing model.
$${\color{red}If\ this\ custom\ node\ helps\ you\ or\ you\ like\ my\ work,\ please\ give\ me⭐on\ this\ repo!}$$ $${\color{red}It's\ a\ greatest\ encouragement\ for\ my\ efforts!}$$
Updates
- 2024/11/11: Added new features and bug fixes. Refer to update.md for details.
- Text-to-Image Generation
- Image Editing
- Support for Multiple Input Images
- Memory Optimization Options
- Flexible Image Size Control
Installation
1. ComfyUI-Manager
- Search for
ComfyUI-OmniGenon ComfyUI Manager and install it. - Restart ComfyUI
2. Git Clone
- Open the terminal on the ComfyUI
ComfyUI/custom_nodesfolder - Run
git clone https://github.com/1038lab/ComfyUI-OmniGen.git - Restart ComfyUI
Install the required Python packages:
- Open the terminal on the
ComfyUI/custom_nodes/ComfyUI-OmniGenfolder ..\..\..\python_embeded\python.exe -m pip install -r requirements.txt
The node includes automatic downloading of:
- OmniGen code from GitHub repository
- Model weights from Hugging Face
No manual file downloading is required. The node will handle everything automatically on first use.</details>
[!IMPORTANT] The first time you use this custom node, it will automatically download the model from Hugging Face. Please be patient, as the download size is approximately 15.5 GB, and it may take some time to complete.
Alternatively, you can manually download the model from Hugging Face at the following link: Download OmniGen-v1 from Hugging Face After downloading, place the model in the following directory:
comfyui/models/LLM/OmniGen-v1
Example workflows
Simple usage for text to image & image to image. workflow
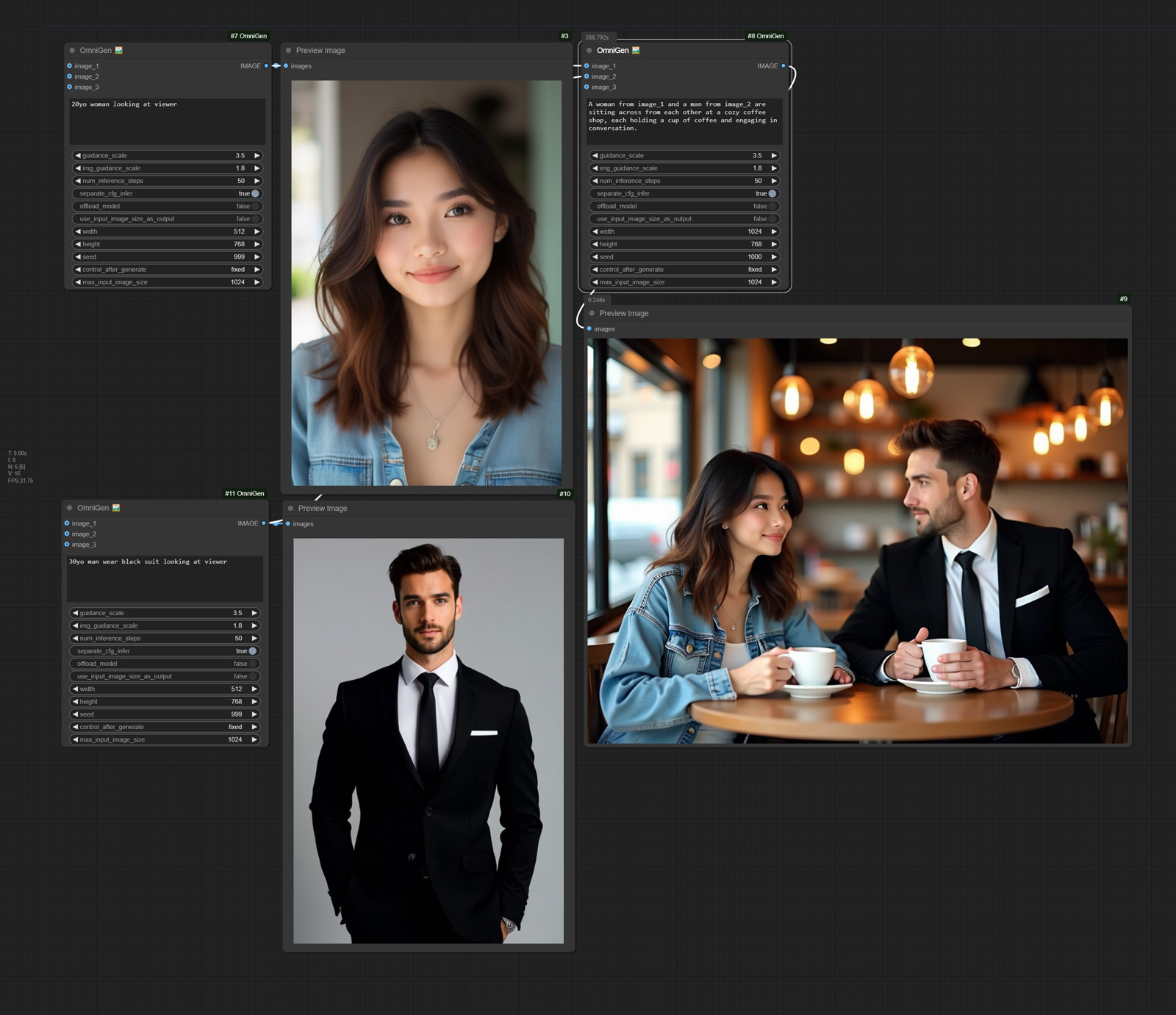
Generate an image that combines 2 images. Workflow
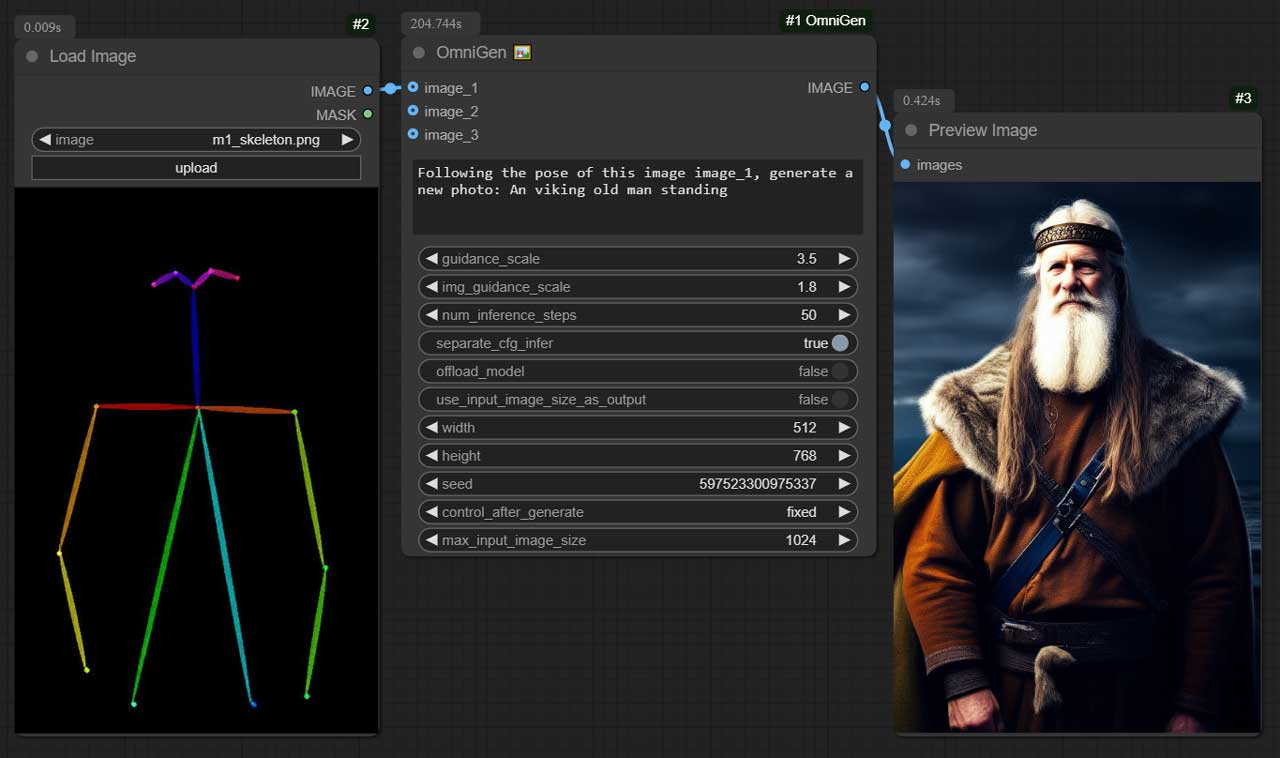
Following the pose of this image image_1, generate a new photo: An viking old man standing.
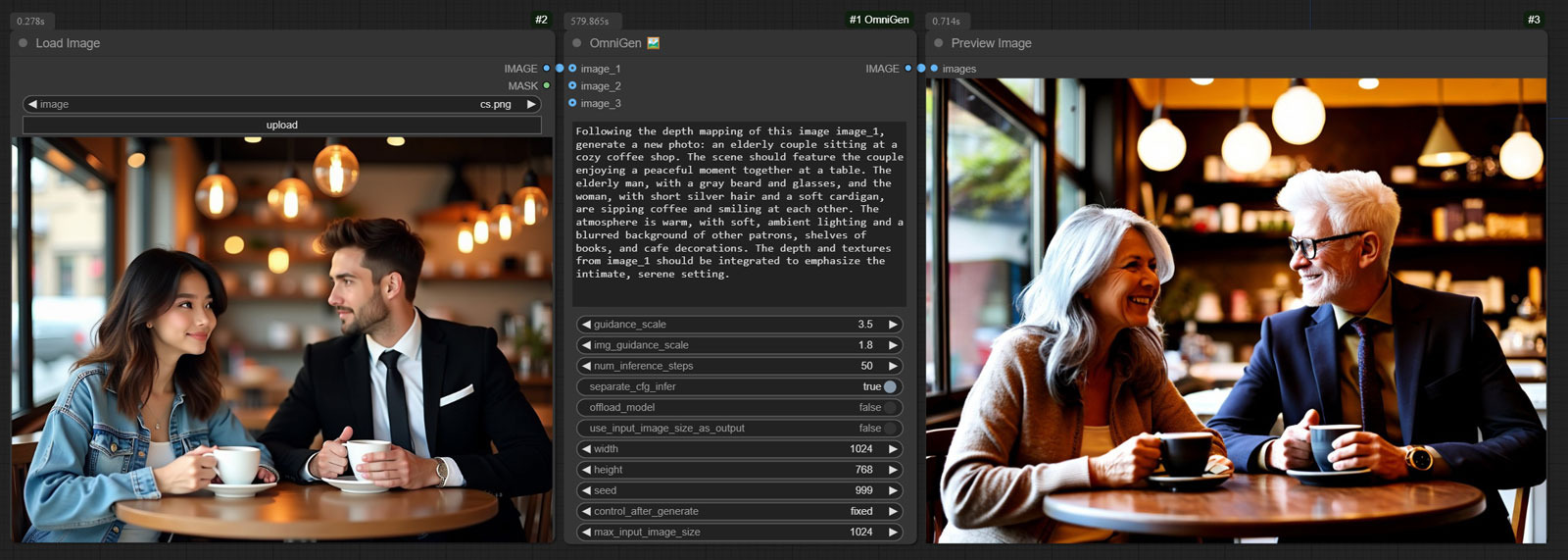
Generate a depth map from the input image and create a new image based on the depth map. Workflow
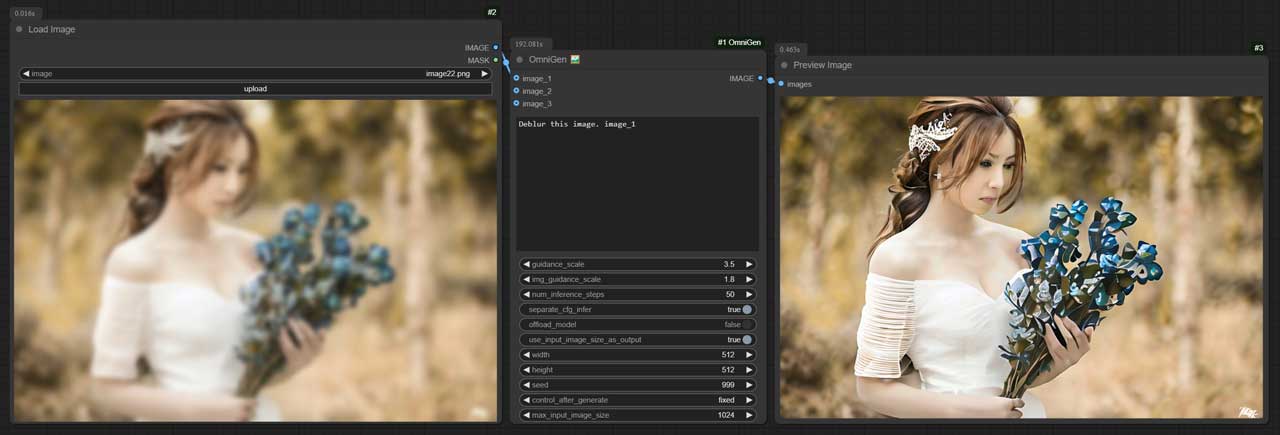
Deblur this image. image_1
Example prompts:
| Prompt | Image_1 | Image_2 | Image_3 | Output |
| ------ | ------ | ------ | ------ | ------ |
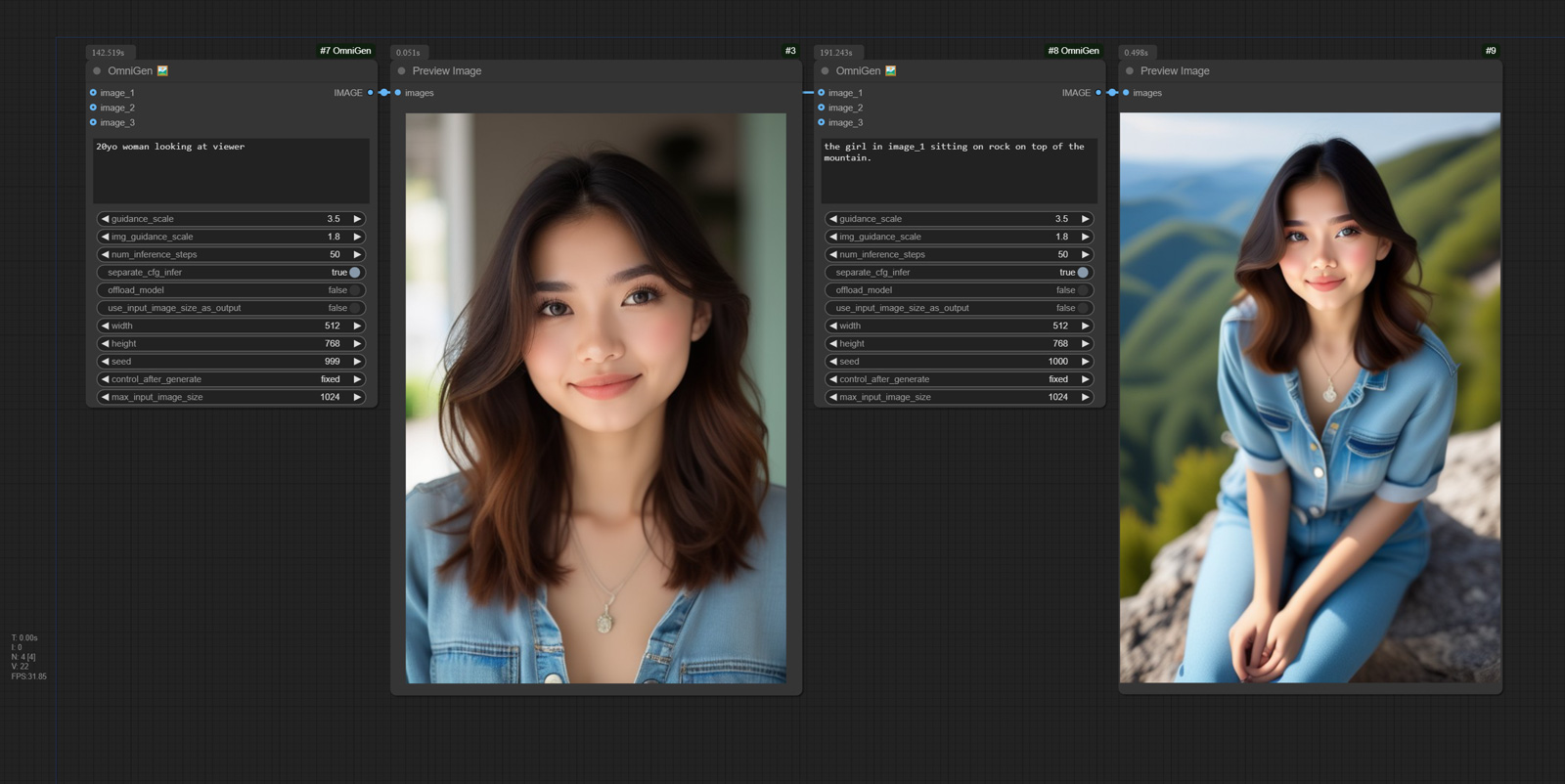
| 20yo woman looking at viewer | | | |  |
| Transform
|
| Transform image_1 into an oil painting | | | |  |
| Transform
|
| Transform image_2 into an Anime |  | | |
| | |  |
| The girl in
|
| The girl in image_1 sitting on rock on top of the mountain. | | | |  |
| Combine
|
| Combine image_1 and image_2 in anime style. | | | |  |
| A woman from
|
| A woman from image_1 and a man from image_2 are sitting across from each other at a cozy coffee shop, each holding a cup of coffee and engaging in conversation. | | | |  |
| Following the depth mapping of this image
|
| Following the depth mapping of this image image_1, generate a new photo: an elderly couple sitting at a cozy coffee shop. The scene should feature the couple enjoying a peaceful moment together at a table. The elderly man, with a gray beard and glasses, and the woman, with short silver hair and a soft cardigan, are sipping coffee and smiling at each other. The atmosphere is warm, with soft, ambient lighting and a blurred background of other patrons, shelves of books, and cafe decorations. The depth and textures from image_1 should be integrated to emphasize the intimate, serene setting. | | | |  |
| Detect the skeleton of a human in this image:
|
| Detect the skeleton of a human in this image: image_1 | | | | 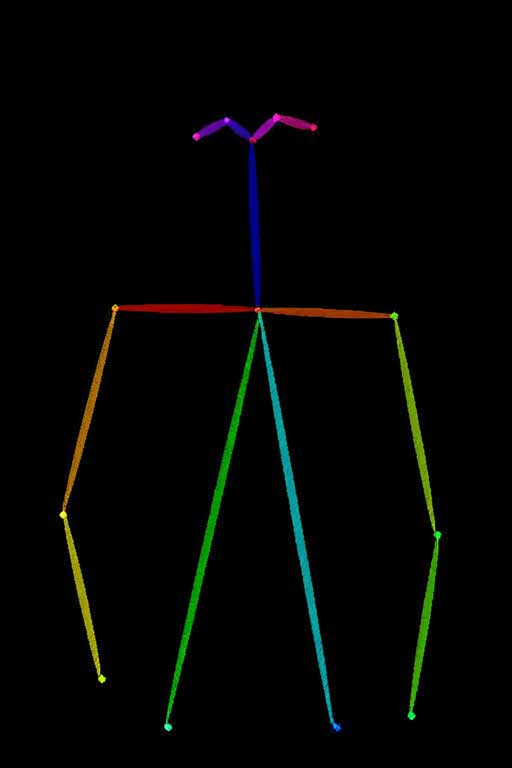 |
| Following the pose of this image
|
| Following the pose of this image image_1, generate a new photo: A viking old man standing | | | |  |
| Detect the depth map of a human in this image:
|
| Detect the depth map of a human in this image: image_1 | | | |  |
| Deblur this image:
|
| Deblur this image: image_1 |  | | |
| | |  |
|
You can reference input images in your prompt using either format:
<img><|image_1|></img>,<img><|image_2|></img>,<img><|image_3|></img>image_1,image_2,image_3image1,image2,image3
Usage
The node will automatically download required files on first use:
- OmniGen code from GitHub
- Model weights from Hugging Face (Shitao/OmniGen-v1)
Input Parameters
prompt: Text description of the desired imagenum_inference_steps: Number of denoising steps (default: 50)guidance_scale: Text guidance scale (default: 2.5)img_guidance_scale: Image guidance scale (default: 1.6)max_input_image_size: Maximum size for input images (default: 1024)width/height: Output image dimensions (default: 1024x1024)seed: Random seed for reproducibility
Memory Optimization Options
separate_cfg_infer: Separate inference process for different guidance (default: True)offload_model: Offload model to CPU to reduce memory usage (default: True)use_input_image_size_as_output: Match output size to input image (default: False)
- Model Weights: Shitao/OmniGen-v1