Nodes Browser
ComfyDeploy: How ComfyUI-StyleTransferPlus works in ComfyUI?
What is ComfyUI-StyleTransferPlus?
Nodes:Neural Neighbor, CAST, EFDM, MicroAST, Coral Color Transfer.
How to install it in ComfyDeploy?
Head over to the machine page
- Click on the "Create a new machine" button
- Select the
Editbuild steps - Add a new step -> Custom Node
- Search for
ComfyUI-StyleTransferPlusand select it - Close the build step dialig and then click on the "Save" button to rebuild the machine
ComfyUI-StyleTransferPlus
Advance Non-Diffusion-based Style Transfer in ComfyUI
Click name to jump to workflow
- Neural Neighbor. Paper: Neural Neighbor Style Transfer
- CAST. Paper: Domain Enhanced Arbitrary Image Style Transfer via Contrastive Learning
- EFDM. Paper: Exact Feature Distribution Matching for Arbitrary Style Transfer and Domain Generalization
- MicroAST. Paper: Towards Super-Fast Ultra-Resolution Arbitrary Style Transfer
- UniST. Paper: Two Birds, One Stone: A Unified Framework for Joint Learning of Image and Video Style Transfers
- AesPA-Net. Paper: Aesthetic Pattern-Aware Style Transfer Networks
- TSSAT. Paper: Two-Stage Statistics-Aware Transformation for Artistic Style Transfer
- AesFA. Paper: An Aesthetic Feature-Aware Arbitrary Neural Style Transfer
More will come soon
Workflows
All nodes support batched input (i.e video) but is generally not recommended. One should generate 1 or 2 style frames (start and end), then use ComfyUI-EbSynth to propagate the style to the entire video.
| Neural Neighbor (2020-2022) - Slowest | CAST (2022-2023) - Fast |
| :-----------------------------------------------------: | :------------------------------------------: |
|  |
|  |
| EFDM (2022) - Fast | MicroAST (2023) - Fast |
|
|
| EFDM (2022) - Fast | MicroAST (2023) - Fast |
|  |
|  |
| UniST (2023) - Medium - Only squares | AesPA-Net (2023) - Medium - Only squares |
|
|
| UniST (2023) - Medium - Only squares | AesPA-Net (2023) - Medium - Only squares |
|  |
|  |
| TSSAT (2023) - Slow | AesFA (2024) - Fast - Only squares |
|
|
| TSSAT (2023) - Slow | AesFA (2024) - Fast - Only squares |
|  |
|  |
|
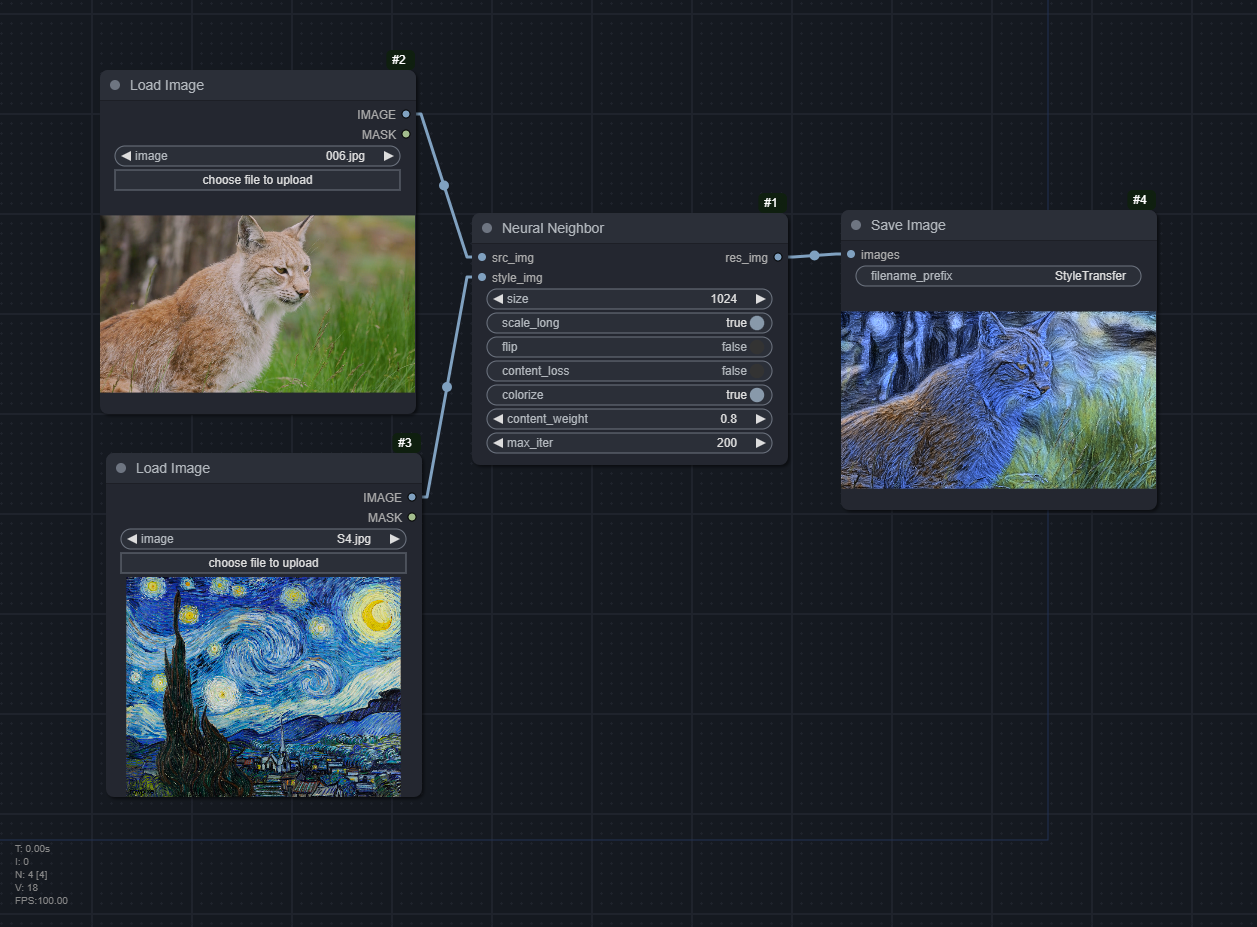
Neural Neighbor
Arguments:
size: Either512or1024, to be used for scaling the images. 1024 takes ~6-12 GB of VRAM. Defaults to512scale_long: Scale by the longest (or shortest side) tosize. Defaults toTrueflip: Augment style image with rotations. Slows down algorithm and increases memory requirement. Generally improves content preservation but hurts stylization slightly. Defaults toFalsecontent_loss: Defaults toTrueUse experimental content loss. The most common failure mode of our method is that colors will shift within an object creating highly visible artifacts, if that happens this flag can usually fix it, but currently it has some drawbacks which is why it isn't enabled by default [...]. One advantage of using this flag though is that [content_weight] can typically be set all the way to 0.0 and the content will remain recognizable.
colorize: Whether to apply color correction. Defaults toTruecontent_weight: weight = 1.0 corresponds to maximum content preservation, weight = 0.0 is maximum stylization (Defaults to 0.75)max_iter: How long each optimization step should take.size=512does 4 scaling steps * max_iter.size=1024does 5. The longer, the better and sharper the result.
See more information on the original repository. No model is needed.
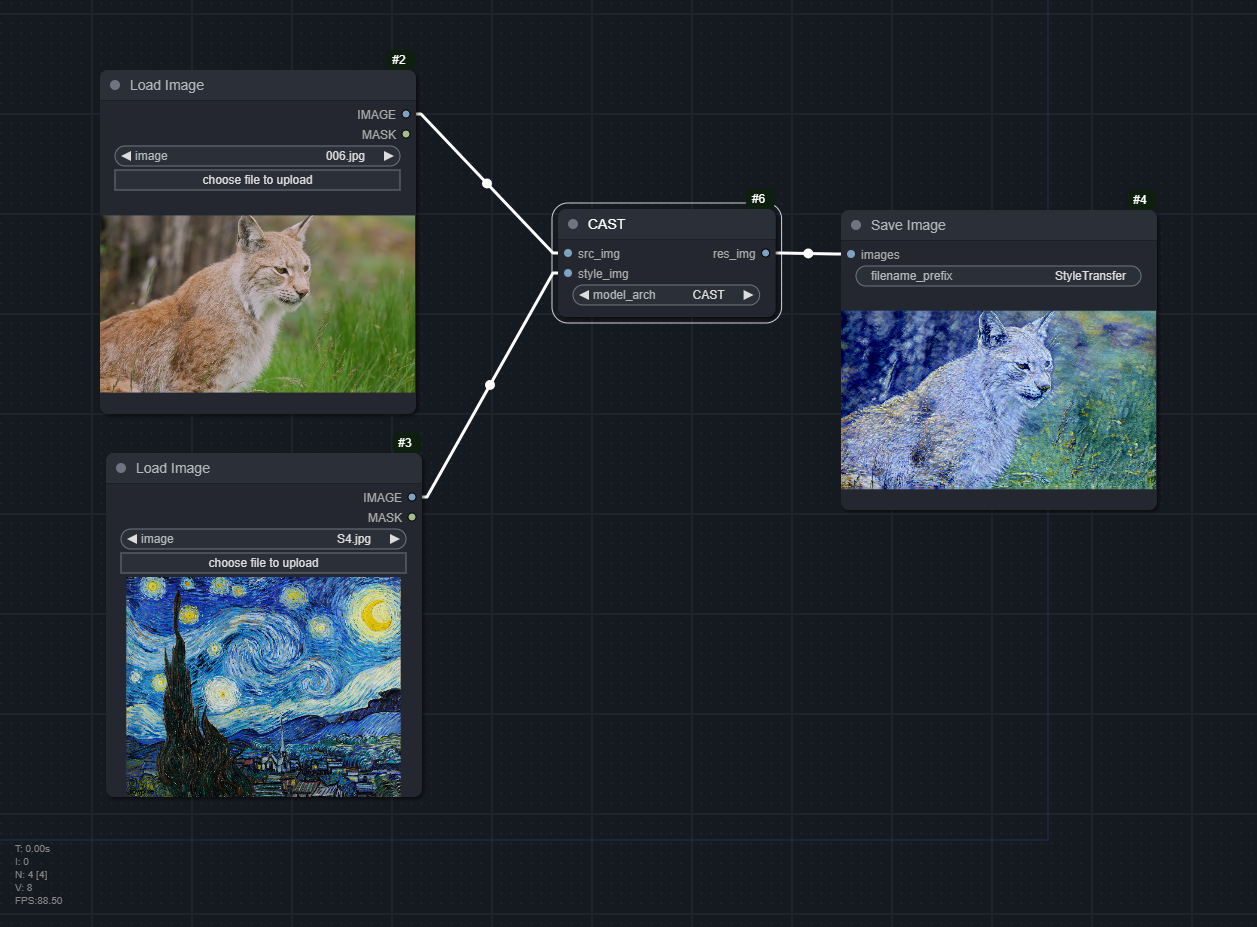
CAST
Download the CAST and UCAST models in the Test section (Google Drive) (Unzip).
Download the vgg_normalized.pth model in the Train section
models/
│ .gitkeep
│ vgg_normalised.pth
─CAST_model
│ latest_net_AE.pth
│ latest_net_Dec_A.pth # Safe to delete
│ latest_net_Dec_B.pth
│ test_opt.txt # Safe to delete
│
└─UCAST_model
latest_net_AE.pth
latest_net_Dec_A.pth # Safe to delete
latest_net_Dec_B.pth
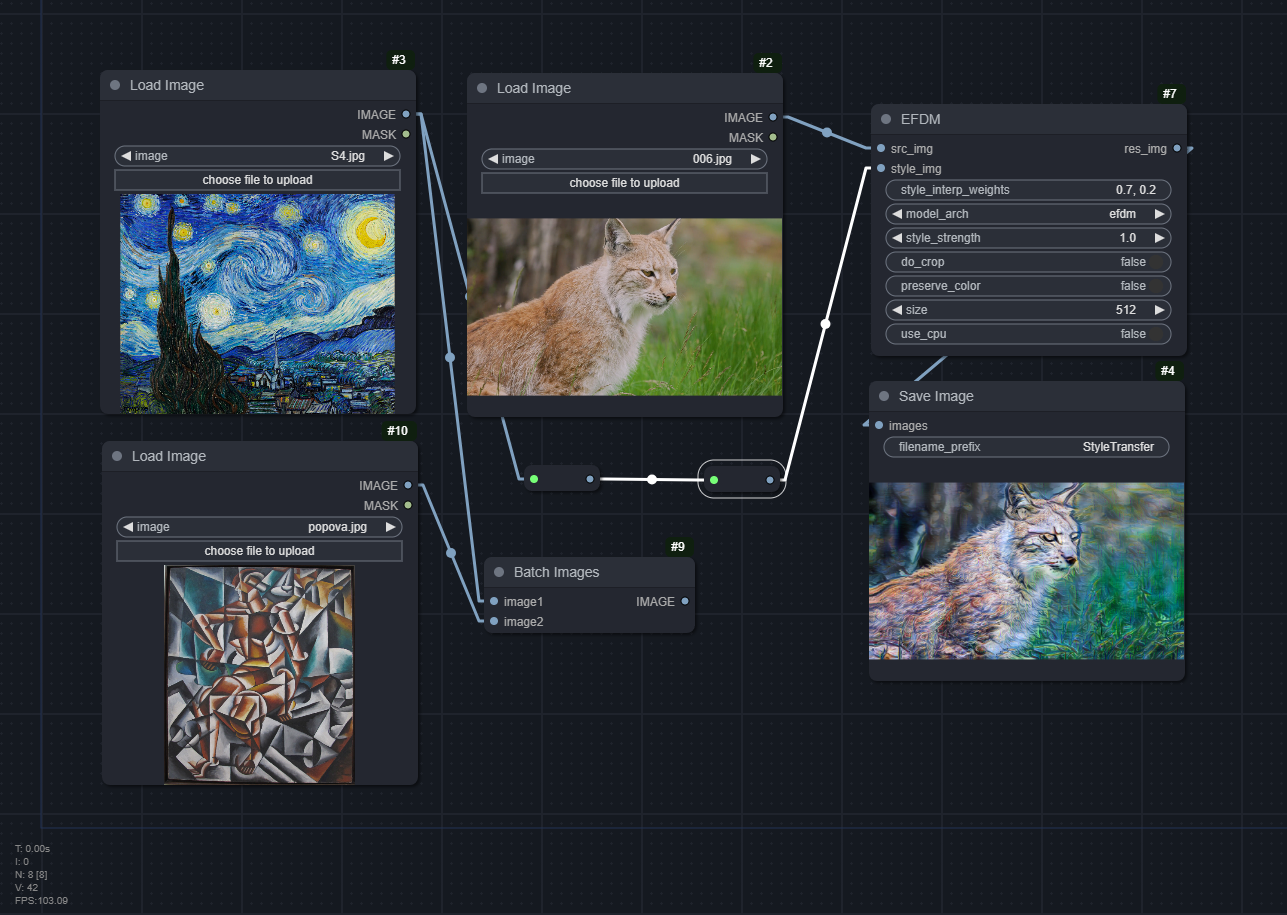
EFDM
Download the hm_decoder_iter_160000.pth
in https://github.com/YBZh/EFDM/tree/main/ArbitraryStyleTransfer/models and put it in
models/hm_decoder_iter_160000.pth
Download vgg_normalized.pth as instructed in CAST
Arguments:
style_interp_weights: Weight for each style (only applicable for multiple styles). If empty, each style will have same weight (1/num_styles). Weights are automatically normalized so you can just enter anythingmodel_arch:["adain", "adamean", "adastd", "efdm", "hm"], defaults to"efdm"style_strength: From 0.00 to 1.00. The higher the stronger the style. Defaults to 1.00do_crop: Whether to resize and then crop the content and style images tosize x sizeor just resize. Defaults to Falsepreserve_color: Whether to preserve the color of the content image. Defaults to Falsesize: Size of the height of the images after resizing. The aspect ratio of content is kept, while the styles will be resized to match content's height and width. The higher thesize, the better the result, but also the more VRAM it will take. You may tryuse_cputo circumvent OOM. Tested withsize=2048on 12GB VRAM.use_cpu: Whether to use CPU or GPU for this. CPU takes very long! (default workflow = ~21 seconds). Defaults to False.
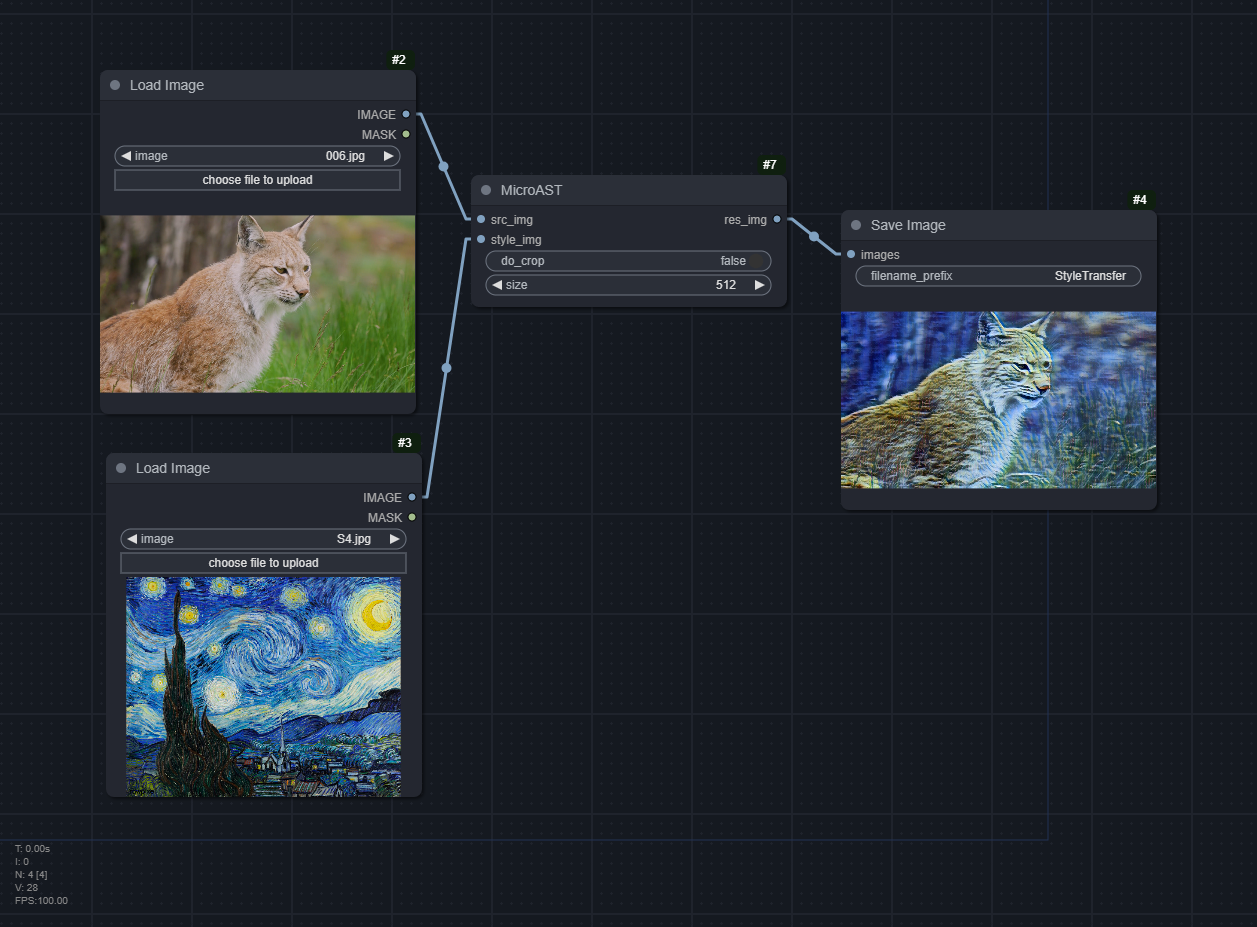
MicroAST
Download models from https://github.com/EndyWon/MicroAST/tree/main/models and place them in the models folder
models/microast/content_encoder_iter_160000.pth.tar
models/microast/decoder_iter_160000.pth.tar
models/microast/modulator_iter_160000.pth.tar
models/microast/style_encoder_iter_160000.pth.tar
Arguments: Similar to EFDM
UniST
Download UniST_model.pt in Testing and vgg_r41.pth, dec_r41.pth in Training section and place them in
models/unist/UniST_model.pt
models/unist/dec_r41.pth
models/unist/vgg_r41.pth
The model only works with square images, so inputs are resized to size x size. do_crop will resize height, then crop to square.
The Video node is "more native" than the Image node for batched images (video) inputs. The model works with batch=3 (3 consecutive frames), so we split the video into such.
| UniST | UniST Video |
| :-----------------------------------------------------------: | :--------------------------------------------------------------: |
| workflow_unist_image.json | workflow_unist_video.json |
| 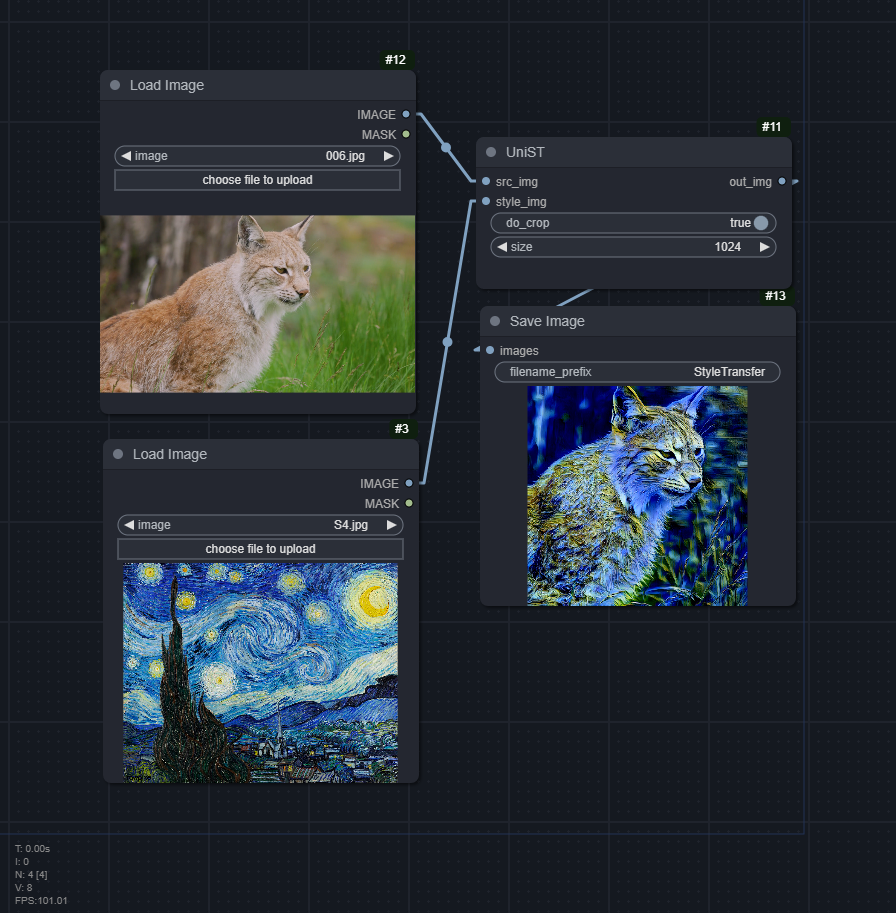 |
| 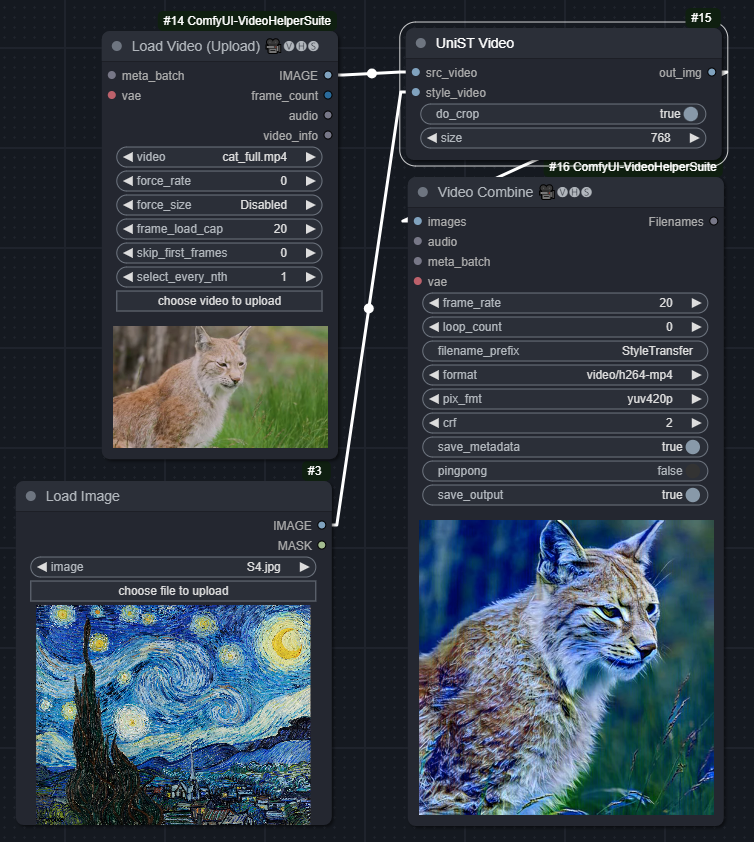 |
| | (Not a workflow-embedded image) |
|
| | (Not a workflow-embedded image) |
AesPA-Net
Download models from Usage section.
For the VGG model, download vgg_normalised_conv5_1.pth from https://github.com/pietrocarbo/deep-transfer/tree/master/models/autoencoder_vgg19/vgg19_5
models/aespa/dec_model.pth
models/aespa/transformer_model.pth
models/aespa/vgg_normalised_conv5_1.pth
The original authors provided a vgg_normalised_conv5_1.t7 model, which can only be opened with torchfile, and pyTorch has dropped native support for it. It also doesn't work reliably on Windows.
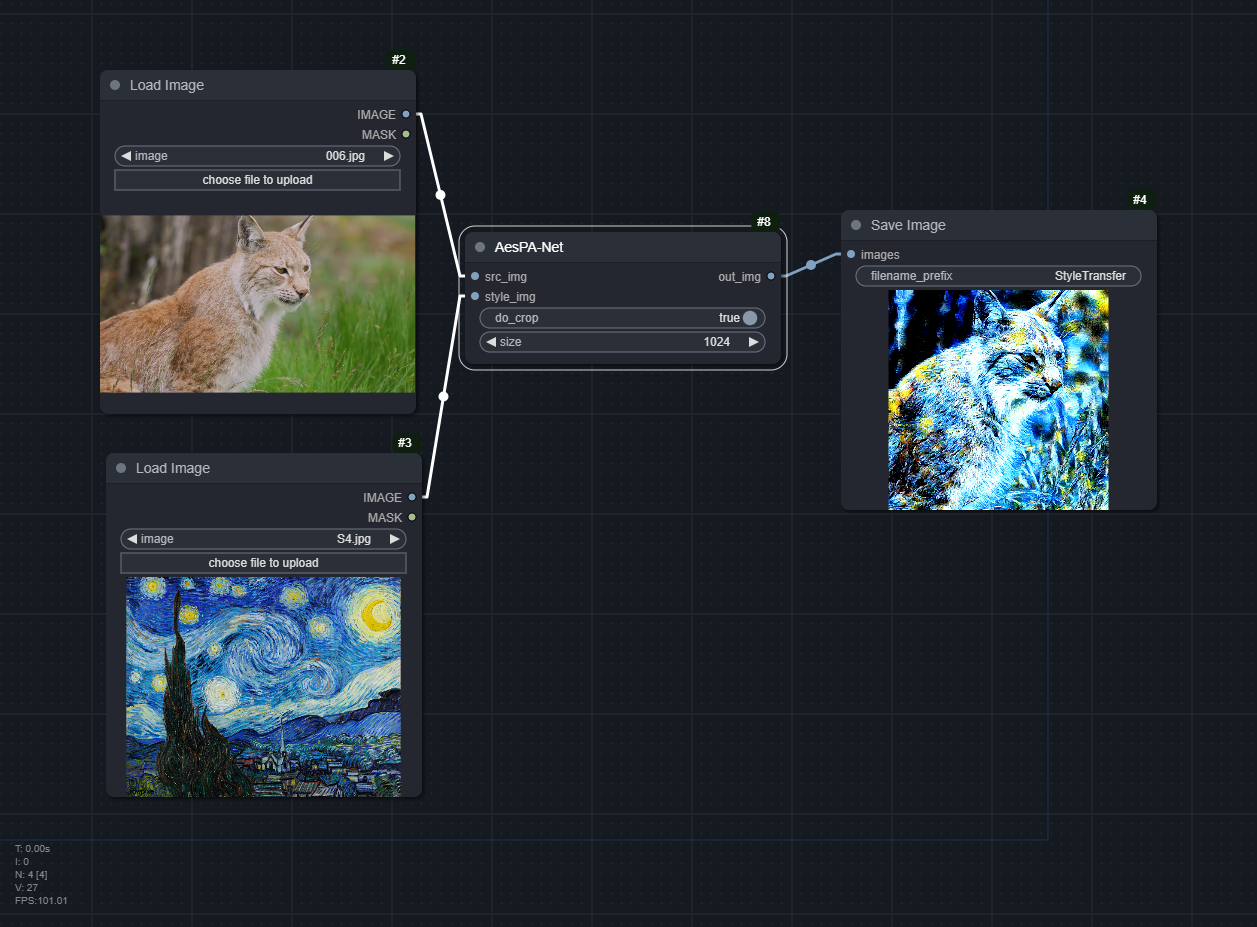
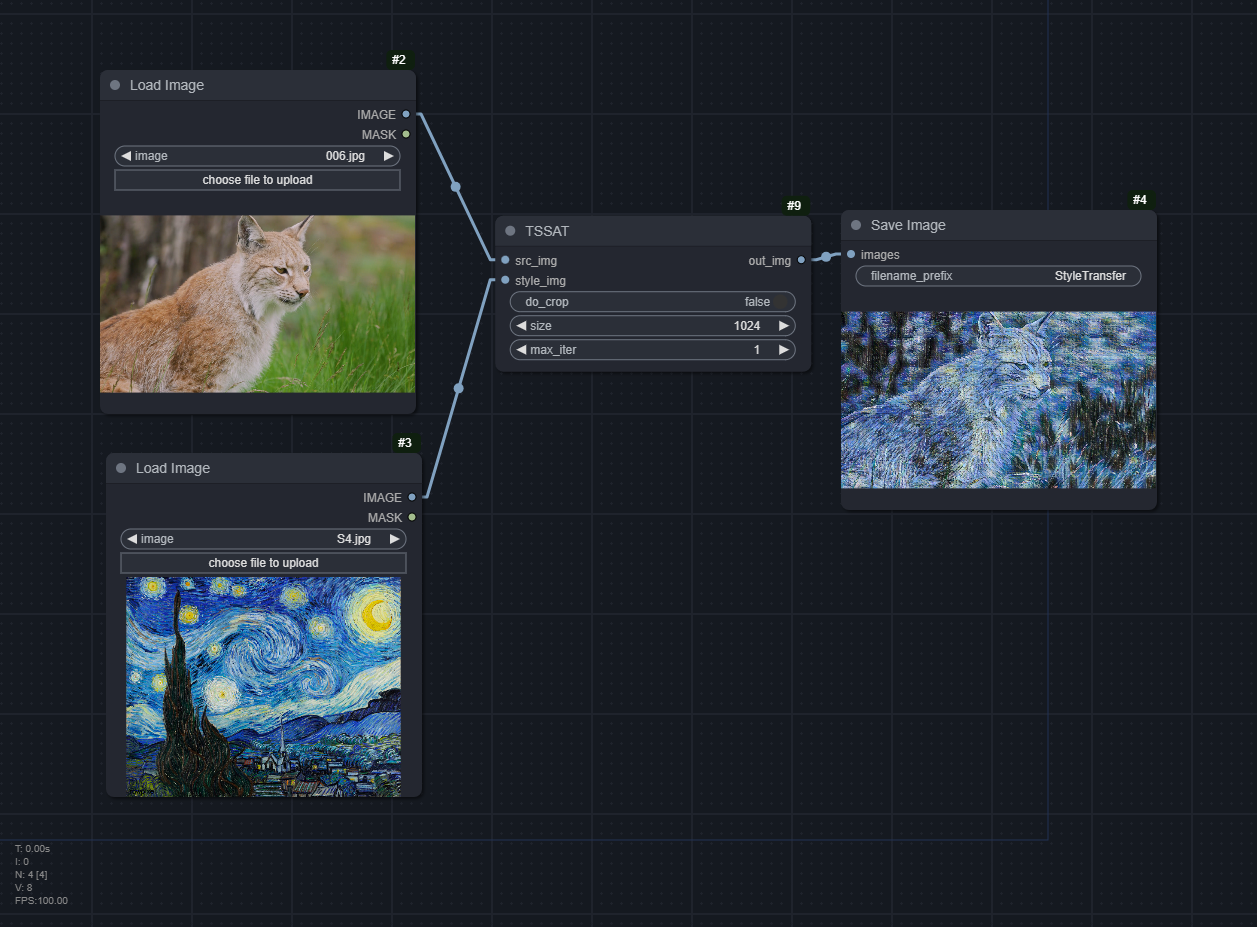
TSSAT
Download the TSSAT-model.zip in the Model Testing section, and unzip it
models/tssat/decoder_iter_160000.pth
# Outside folder, can be ignored from the zip if already downloaded from above
models/vgg_normalised.pth
AesFA
Download main.pth in the Getting Started and place it in models/aesfa/main.pth.
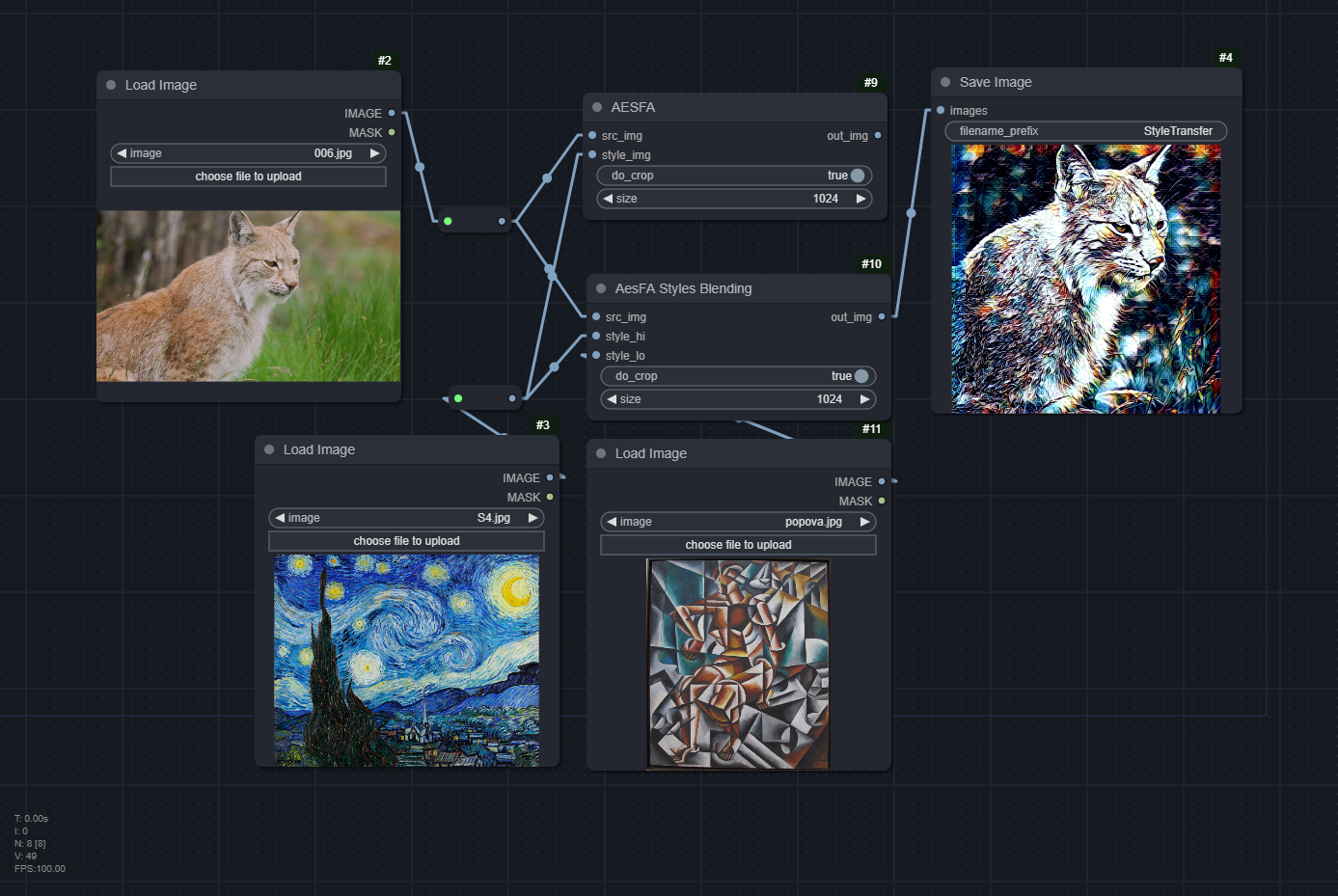
Authors' Notes:
[...] style blending, i.e., using the low-frequency and high-frequency style information from different images. The style-transferred outputs finely keep the color information from the low-frequency image and change the texture information based on the high frequency image.
The vertical line-shape artifacts alongside the images are often observed. We reason that these appear because the content features are being convolved directly with the predicted aesthetic feature-aware kernels and biases in our model. In addition, the upsampling operation could be the ones that create artifacts.
Extra nodes
Coral Color Transfer
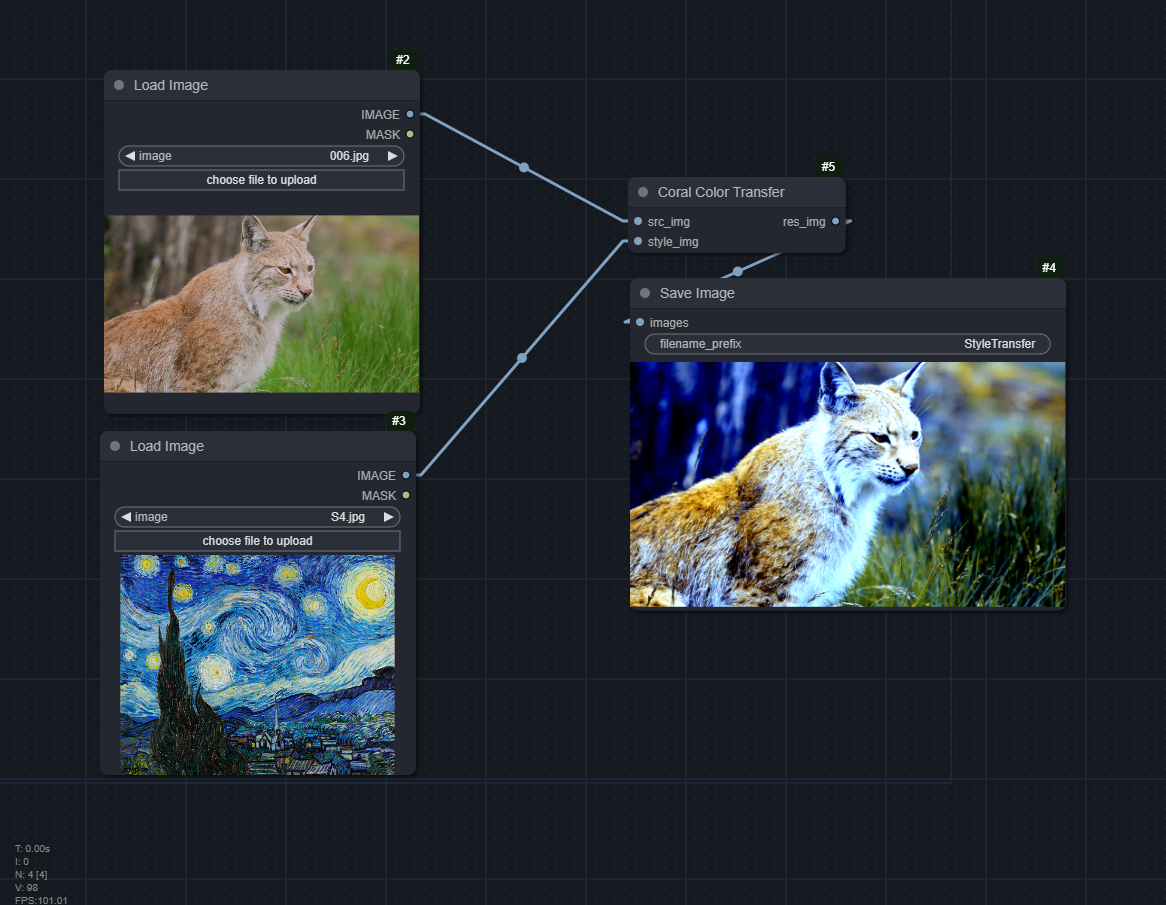
Credits
@inproceedings{zhang2020cast,
author = {Zhang, Yuxin and Tang, Fan and Dong, Weiming and Huang, Haibin and Ma, Chongyang and Lee, Tong-Yee and Xu, Changsheng},
title = {Domain Enhanced Arbitrary Image Style Transfer via Contrastive Learning},
booktitle = {ACM SIGGRAPH},
year = {2022}
}
@article{zhang2023unified,
title={A Unified Arbitrary Style Transfer Framework via Adaptive Contrastive Learning},
author={Zhang, Yuxin and Tang, Fan and Dong, Weiming and Huang, Haibin and Ma, Chongyang and Lee, Tong-Yee and Xu, Changsheng},
journal={ACM Transactions on Graphics},
year={2023},
publisher={ACM New York, NY}
}
@inproceedings{zhang2021exact,
title={Exact Feature Distribution Matching for Arbitrary Style Transfer and Domain Generalization},
author={Zhang, Yabin and Li, Minghan and Li, Ruihuang and Jia, Kui and Zhang, Lei},
booktitle={CVPR},
year={2022}
}
@inproceedings{wang2023microast,
title={MicroAST: Towards Super-Fast Ultra-Resolution Arbitrary Style Transfer},
author={Wang, Zhizhong and Zhao, Lei and Zuo, Zhiwen and Li, Ailin and Chen, Haibo and Xing, Wei and Lu, Dongming},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
year={2023}
}
@InProceedings{Gu_2023_ICCV,
author = {Gu, Bohai and Fan, Heng and Zhang, Libo},
title = {Two Birds, One Stone: A Unified Framework for Joint Learning of Image and Video Style Transfers},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2023},
pages = {23545-23554}
}
@article{Hong2023AesPANetAP,
title={AesPA-Net: Aesthetic Pattern-Aware Style Transfer Networks},
author={Kibeom Hong and Seogkyu Jeon and Junsoo Lee and Namhyuk Ahn and Kunhee Kim and Pilhyeon Lee and Daesik Kim and Youngjung Uh and Hyeran Byun},
journal={ArXiv},
year={2023},
volume={abs/2307.09724},
url={https://api.semanticscholar.org/CorpusID:259982728}
}