Nodes Browser
ComfyDeploy: How ComfyUI_CaptionThis works in ComfyUI?
What is ComfyUI_CaptionThis?
Describe a single image or all images in a directory using models such as Janus Pro, Florence2, or JoyCaption (testing), with a particular focus on building datasets for training LoRA.
How to install it in ComfyDeploy?
Head over to the machine page
- Click on the "Create a new machine" button
- Select the
Editbuild steps - Add a new step -> Custom Node
- Search for
ComfyUI_CaptionThisand select it - Close the build step dialig and then click on the "Save" button to rebuild the machine
ComfyUI-CaptionThis
ComfyUI-CaptionThis is a flexible tool for generating image captions, supporting several powerful captioning models such as Janus Pro and Florence2, with plans to integrate more models like JoyCaption and other future developments. This tool aims to simplify workflows for image-to-image tasks and LoRA dataset preparation or similar fine-tuning processes, providing an intuitive way to describe individual images or batch process entire directories.
Important Updates
- 2025/02/16: Added support for the Florence2 model.
- 2025/02/15: Added support for the Janus Pro model.
Workflow
A ShowText or DisplayText node is required to display the results of command execution. However, ComfyUI currently does not provide a native node for this purpose. In my example, I used the self-implemented MieNodes (GitHub Repo), which I highly recommend. It’s easy to install, has no dependencies, and includes many caption-related file operation nodes.
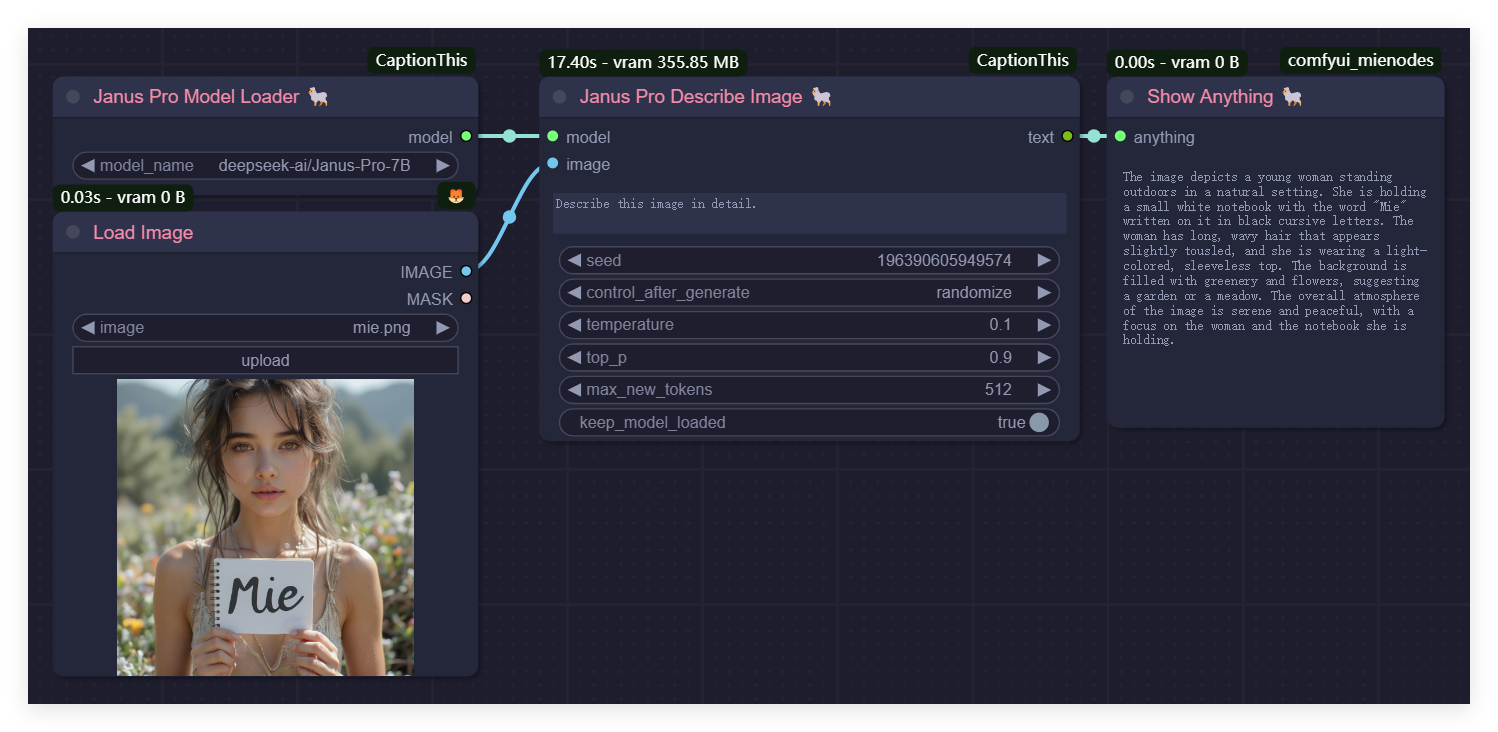
Describe an Image Using Janus Pro
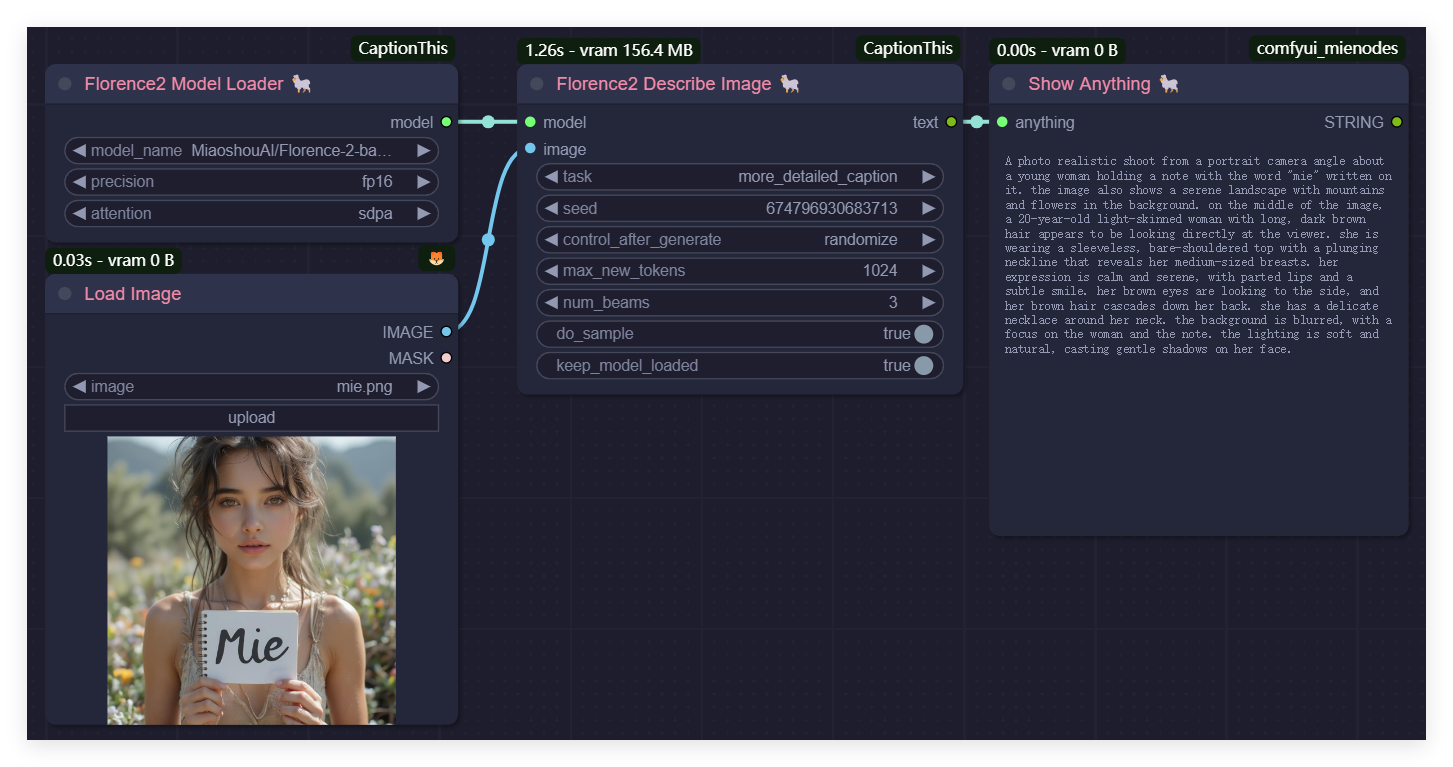
Describe an Image Using Florence2
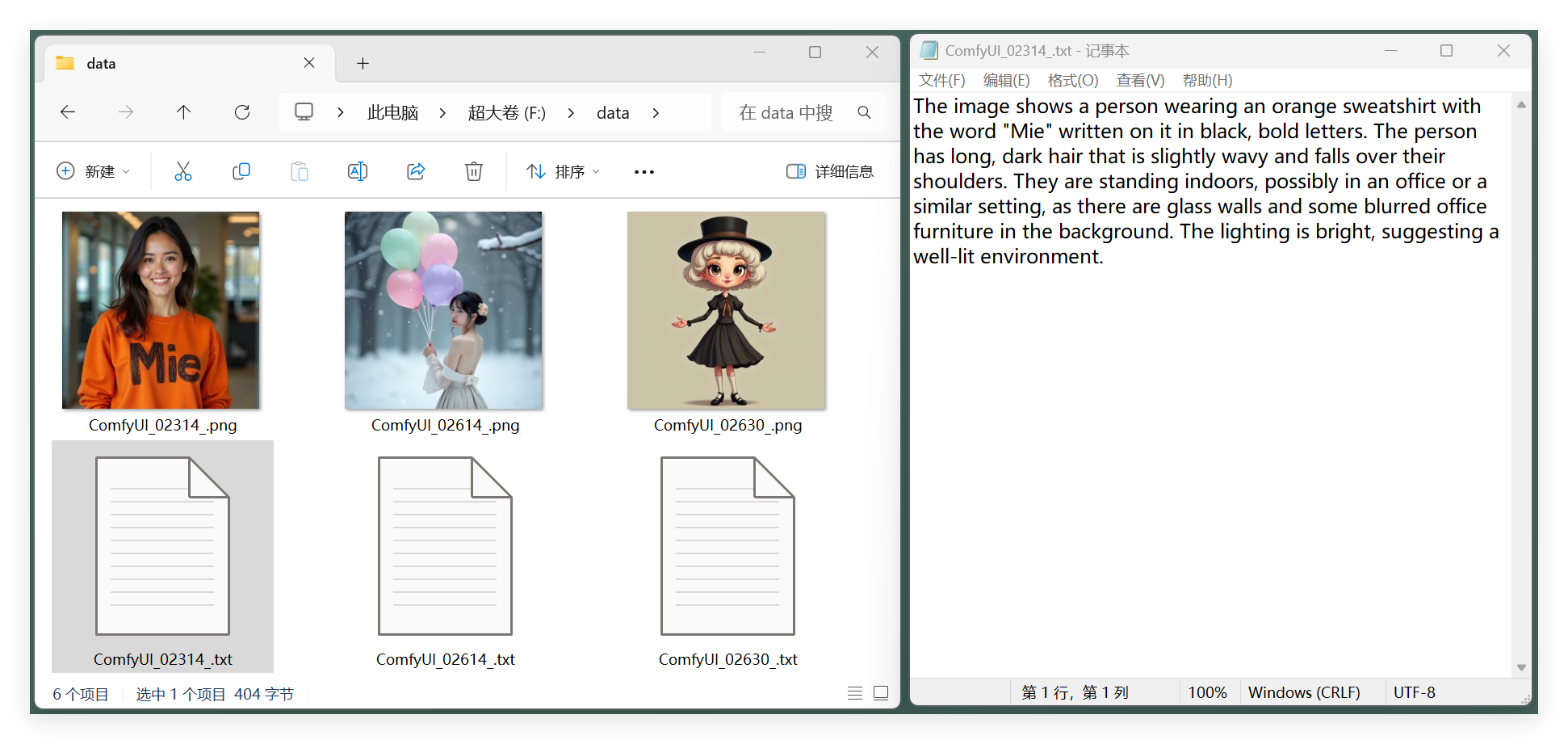
Generate Captions for All Images in a Directory Using Janus Pro
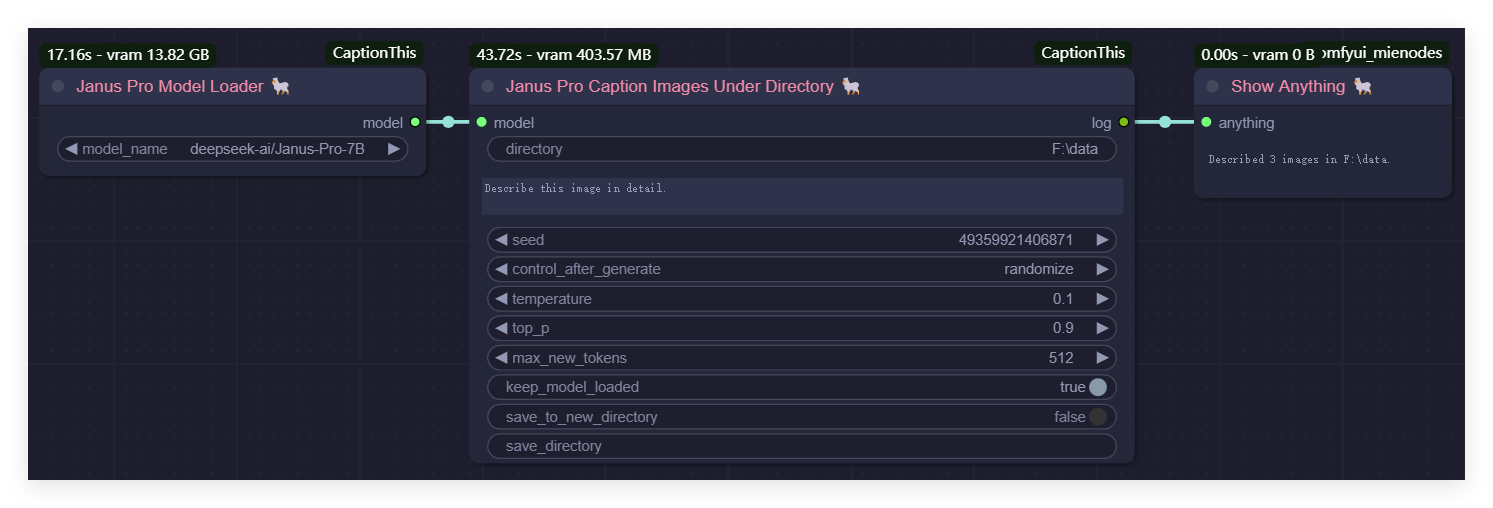
Before:
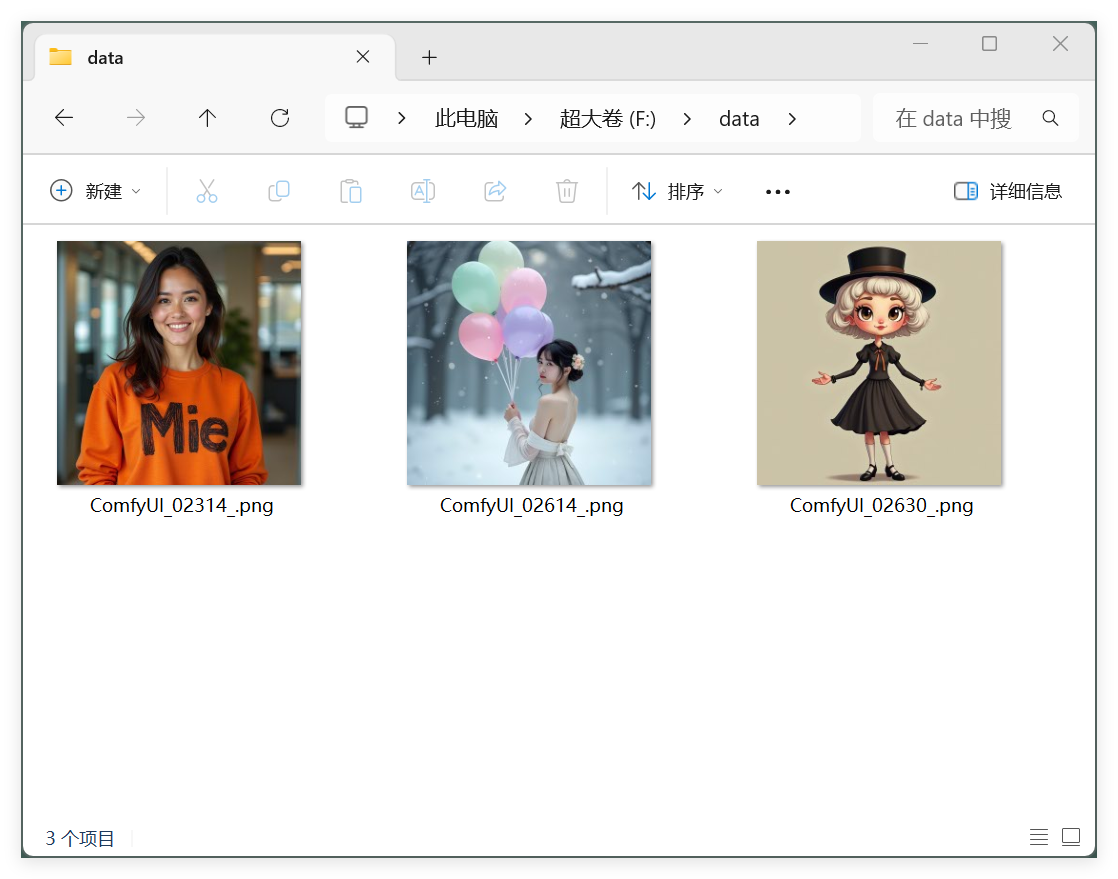
After:
Generate Captions for All Images in a Directory Using Florence2
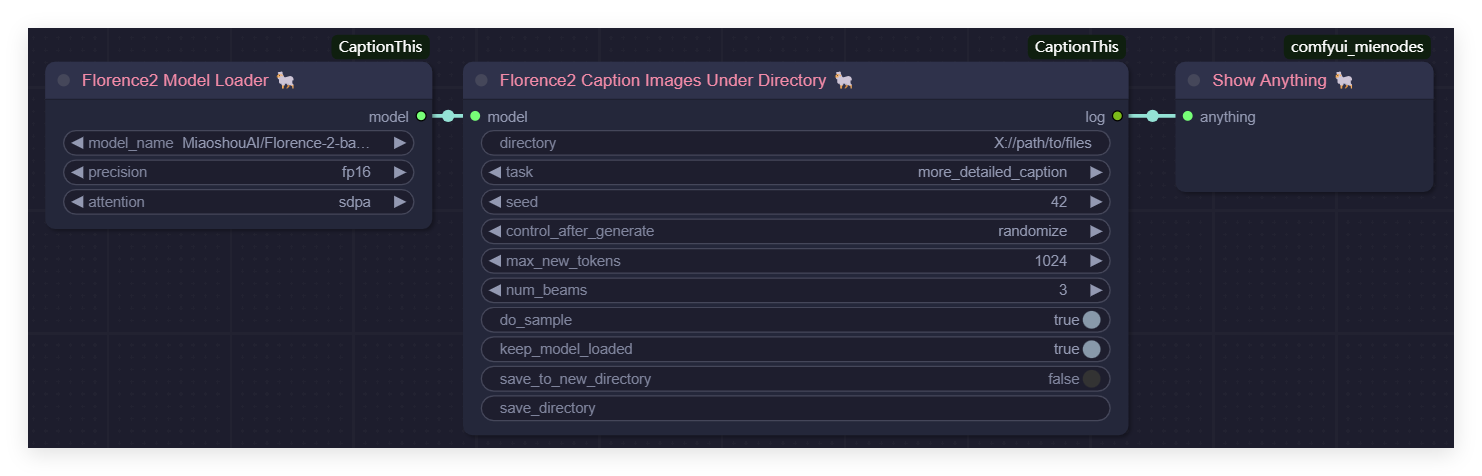
The process is the same as Janus Pro.
Installation
Install via ComfyUI Manager (Recommended)
- Install ComfyUI-Manager.
- Search for "CaptionThis" in the manager.
- Click Install.
Model Download
Currently, all models are downloaded directly from HuggingFace (or via hf_mirror if you specify the environment variable HF_ENDPOINT=https://hf-mirror.com). Alternatively, you can manually download the models and place them in the directories outlined below.
Janus Pro
- Download the models:
- Place the models in the directory
ComfyUI/models/Janus-Pro/as follows:ComfyUI/models/Janus-Pro/Janus-Pro-1B/ ComfyUI/models/Janus-Pro/Janus-Pro-7B/
Florence2
- Download the models:
- Place the models in the directory
ComfyUI/models/LLM/as follows:ComfyUI/models/LLM/Florence-2-base/ ComfyUI/models/LLM/Florence-2-base-ft/ ComfyUI/models/LLM/Florence-2-large/ ComfyUI/models/LLM/Florence-2-large-ft/ ComfyUI/models/LLM/Florence-2-base-PromptGen-v1.5/ ComfyUI/models/LLM/Florence-2-large-PromptGen-v1.5/ ComfyUI/models/LLM/Florence-2-base-PromptGen-v2.0/ ComfyUI/models/LLM/Florence-2-large-PromptGen-v2.0/
Features
-
Single Image Description Generate detailed captions for an individual image using your chosen model. Users can upload an image and optionally provide specific prompts or guiding questions to enrich the output.
-
Batch Caption Generation Automatically generate captions for multiple images within a specified directory. Each image will have its corresponding description saved as a
.txtfile, streamlining the process of dataset preparation. -
Multi-Model Support The system is designed to support multiple captioning models, giving users the flexibility to choose based on their specific tasks. Currently, the tool supports Janus Pro and Florence2, with plans for future updates to include additional models and expand functionality further.
Coming Soon
- Integration of new models (e.g., JoyCaption) to further enhance the tool’s capabilities and support a broader range of use cases.
- Advanced configuration options to fine-tune caption outputs and tailor them to user-specific requirements.
Credits
Special thanks go to:
- DeepSeek-AI for providing the robust Janus Pro model.
- CY-CHENYUE and kijai for their practical implementations of Janus Pro and Florence2 in respective plugins, which served as key references and inspiration for integrating these models into this project.
Building upon these contributions, this project introduces a refined multi-model architecture, empowering users to select the most appropriate model based on their specific needs.
Contact
- Bilibili: @黎黎原上咩
- YouTube: @SweetValberry