Nodes Browser
ComfyDeploy: How ComfyUI-3D-Pack works in ComfyUI?
What is ComfyUI-3D-Pack?
Make 3D assets generation in ComfyUI good and convenient as it generates image/video! This is an extensive node suite that enables ComfyUI to process 3D inputs (Mesh & UV Texture, etc.) using cutting edge algorithms (3DGS, NeRF, etc.) and models (InstantMesh, CRM, TripoSR, etc.) NOTE: Pre-built python wheels can manually download from [a/https://github.com/MrForExample/Comfy3D_Pre_Builds](https://github.com/MrForExample/Comfy3D_Pre_Builds) if automatic install failed
How to install it in ComfyDeploy?
Head over to the machine page
- Click on the "Create a new machine" button
- Select the
Editbuild steps - Add a new step -> Custom Node
- Search for
ComfyUI-3D-Packand select it - Close the build step dialig and then click on the "Save" button to rebuild the machine
ComfyUI-3D-Pack
Make 3D assets generation in ComfyUI good and convenient as it generates image/video! <br> This is an extensive node suite that enables ComfyUI to process 3D inputs (Mesh & UV Texture, etc.) using cutting edge algorithms (3DGS, NeRF, etc.) and models (InstantMesh, CRM, TripoSR, etc.)
<span style="font-size:1.5em;"> <a href=#Features>Features</a> — <a href=#install>Install</a> — <a href=#roadmap>Roadmap</a> — <a href=#development>Development</a> — <a href=#tips>Tips</a> — <a href=#supporters>Supporters</a> </span>Install:
Can be installed directly from ComfyUI-Manager🚀
- Pre-builds are available for:
- Windows 10/11, Ubuntu 22.04
- Python 3.10/3.11/3.12
- CUDA 12.4/12.1/11.8
- torch 2.3.0/2.4.0/2.5.1+cu124/cu121/cu118
- install.py will download & install Pre-builds automatically according to your runtime environment, if it couldn't find corresponding Pre-builds, then build script will start automatically, if automatic build doesn't work for you, then please check out Semi-Automatic Build Guide
- If you have any missing node in any open Comfy3D workflow, try simply click Install Missing Custom Nodes in ComfyUI-Manager
- If for some reason your comfy3d can't download pre-trained models automatically, you can always download them manually and put them in to correct folder under Checkpoints directory, but please DON'T overwrite any exist .json files
- Docker install please check DOCKER_INSTRUCTIONS.md
- Note: at this moment, you'll still need to install Visual Studio Build Tools for windows and install
gcc g++for Linux in order forInstantNGP & Convert 3DGS to Mesh with NeRF and Marching_Cubesnodes to work, since those two nodes used JIT torch cpp extension that builds in runtime, but I plan to replace those nodes soon
Features:
-
For use cases please check out Example Workflows. [Last update: 08/November/2024]
- Note: you need to put Example Inputs Files & Folders under ComfyUI Root Directory\ComfyUI\input folder before you can run the example workflow
- tripoSR-layered-diffusion workflow by @Consumption
-
Hunyuan3D_V1 tencent/Hunyuan3D-1
- Two stages pipeline:
- Single image to multi-views
- Multi-views to 3D Mesh with RGB texture
- Model weights: https://huggingface.co/tencent/Hunyuan3D-1/tree/main
- Two stages pipeline:
-
StableFast3D: Stability-AI/stable-fast-3d
- Single image to 3D Mesh with RGB texture
- Note: you need to agree to Stability-AI's term of usage before been able to download the model weights, if you downloaded model weights manually, then you need to put it under Checkpoints/StableFast3D, otherwise you can add your huggingface token in Configs/system.conf
- Model weights: https://huggingface.co/stabilityai/stable-fast-3d/tree/main
<video controls autoplay loop src="https://github.com/user-attachments/assets/3ed3d1ed-4abe-4959-bd79-4431d19c9d47"></video>
-
CharacterGen: zjp-shadow/CharacterGen
- Single front view of a character with arbitrary pose
- Can combine with Unique3D workflow for better result
- Model weights: https://huggingface.co/zjpshadow/CharacterGen/tree/main
<video controls autoplay loop src="https://github.com/user-attachments/assets/4f0ae0c0-2d29-49f0-a6f2-a636dd4b4dcc"></video>
-
Unique3D: AiuniAI/Unique3D
- Four stages pipeline:
- Single image to 4 multi-view images with resulution: 256X256
- Consistent Multi-view images Upscale to 512X512, super resolution to 2048X2048
- Multi-view images to Normal maps with resulution: 512X512, super resolution to 2048X2048
- Multi-view images & Normal maps to 3D mesh with texture
- To use the All stage Unique3D workflow, Download Models:
- sdv1.5-pruned-emaonly and put it into
Your ComfyUI root directory/ComfyUI/models/checkpoints - fine-tuned controlnet-tile and put it into
Your ComfyUI root directory/ComfyUI/models/controlnet - ip-adapter_sd15 and put it into
Your ComfyUI root directory/ComfyUI/models/ipadapter - OpenCLIP-ViT-H-14, rename it to OpenCLIP-ViT-H-14.safetensors and put it into
Your ComfyUI root directory/ComfyUI/models/clip_vision - RealESRGAN_x4plus and put it into
Your ComfyUI root directory/ComfyUI/models/upscale_models
- sdv1.5-pruned-emaonly and put it into
- Model weights: https://huggingface.co/spaces/Wuvin/Unique3D/tree/main/ckpt
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/45dd6bfc-4f2b-4b1f-baed-13a1b0722896"></video>
- Four stages pipeline:
-
Era3D MVDiffusion Model: pengHTYX/Era3D
- Single image to 6 multi-view images & normal maps with resulution: 512X512
- Note: you need at least 16GB vram to run this model
- Model weights: https://huggingface.co/pengHTYX/MacLab-Era3D-512-6view/tree/main
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/fc210cac-6c7d-4a55-926c-adb5fb7b0c57"></video>
-
InstantMesh Reconstruction Model: TencentARC/InstantMesh
- Sparse multi-view images with white background to 3D Mesh with RGB texture
- Works with arbitrary MVDiffusion models (Probably works best with Zero123++, but also works with CRM MVDiffusion model)
- Model weights: https://huggingface.co/TencentARC/InstantMesh/tree/main
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/a0648a44-f8cb-4f78-9704-a907f9174936"></video> <video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/33aecedb-f595-4c12-90dd-89d5f718598e"></video>
-
Zero123++: SUDO-AI-3D/zero123plus
- Single image to 6 view images with resulution: 320X320
-
Convolutional Reconstruction Model: thu-ml/CRM
- Three stages pipeline:
- Single image to 6 view images (Front, Back, Left, Right, Top & Down)
- Single image & 6 view images to 6 same views CCMs (Canonical Coordinate Maps)
- 6 view images & CCMs to 3D mesh
- Note: For low vram pc, if you can't fit all three models for each stages into your GPU memory, then you can divide those three stages into different comfy workflow and run them separately
- Model weights: https://huggingface.co/sudo-ai/zero123plus-v1.2
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/cf68bb83-9244-44df-9db8-f80eb3fdc29e"></video>
- Three stages pipeline:
-
TripoSR: VAST-AI-Research/TripoSR | ComfyUI-Flowty-TripoSR
- Generate NeRF representation and using marching cube to turn it into 3D mesh
- Model weights: https://huggingface.co/stabilityai/TripoSR/tree/main
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/ec4f8df5-5907-4bbf-ba19-c0565fe95a97"></video>
-
Wonder3D: xxlong0/Wonder3D
- Generate spatial consistent 6 views images & normal maps from a single image
- Model weights: https://huggingface.co/flamehaze1115/wonder3d-v1.0/tree/main
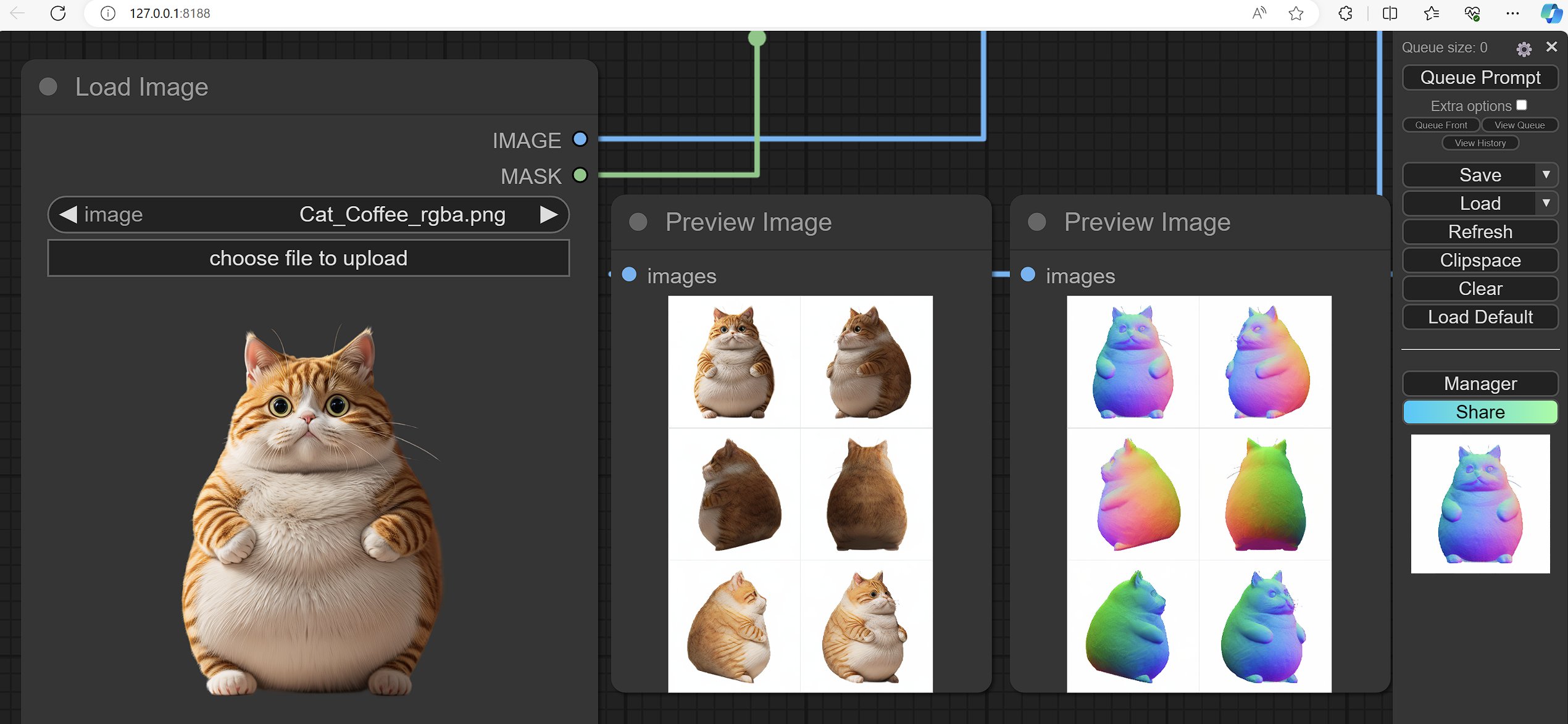
-
Large Multiview Gaussian Model: 3DTopia/LGM
- Enable single image to 3D Gaussian in less than 30 seconds on a RTX3080 GPU, later you can also convert 3D Gaussian to mesh
- Model weights: https://huggingface.co/ashawkey/LGM/tree/main
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/e221d7f8-49ac-4ed4-809b-d4c790b6270e"></video>
-
Triplane Gaussian Transformers: VAST-AI-Research/TriplaneGaussian
- Enable single image to 3D Gaussian in less than 10 seconds on a RTX3080 GPU, later you can also convert 3D Gaussian to mesh
- Model weights: https://huggingface.co/VAST-AI/TriplaneGaussian/tree/main
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/90e7f298-bdbd-4c15-9378-1ca46cbb4871"></video>
-
Preview 3DGS and 3D Mesh: 3D Visualization inside ComfyUI:
- Using gsplat.js and three.js for 3DGS & 3D Mesh visualization respectively
- Custumizable background base on JS library: mdbassit/Coloris
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/9f3c56b1-afb3-4bf1-8845-ab1025a87463"></video>
-
Stack Orbit Camera Poses: Automatically generate all range of camera pose combinations
-
You can use it to conditioning the StableZero123 (You need to Download the checkpoint first), with full range of camera poses in one prompt pass
-
You can use it to generate the orbit camera poses and directly input to other 3D process node (e.g. GaussianSplatting and BakeTextureToMesh)
-
Example usage:
<img src="_Example_Workflows/_Example_Outputs/Cammy_Cam_Rotate_Clockwise_Camposes.png" width="256"/> <img src="_Example_Workflows/_Example_Outputs/Cammy_Cam_Rotate_Counter_Clockwise_Camposes.png" width="256"/> <br> <img src="_Example_Workflows/_Example_Outputs/Cammy_Cam_Rotate_Clockwise.gif" width="256"/> <img src="_Example_Workflows/_Example_Outputs/Cammy_Cam_Rotate_Counter_Clockwise.gif" width="256"/>
-
Coordinate system:
- Azimuth: In top view, from angle 0 rotate 360 degree with step -90 you get (0, -90, -180/180, 90, 0), in this case camera rotates clock-wise, vice versa.
- Elevation: 0 when camera points horizontally forward, pointing down to the ground is negitive angle, vice versa.
-
-
FlexiCubes: nv-tlabs/FlexiCubes
- Multi-View depth & mask (optional normal maps) as inputs
- Export to 3D Mesh
- Usage guide:
- voxel_grids_resolution: determine mesh resolution/quality
- depth_min_distance depth_max_distance : distance from object to camera, object parts in the render that is closer(futher) to camera than depth_min_distance(depth_max_distance) will be rendered with pure white(black) RGB value 1, 1, 1(0, 0, 0)
- mask_loss_weight: Control the silhouette of reconstrocted 3D mesh
- depth_loss_weight: Control the shape of reconstrocted 3D mesh, this loss will also affect the mesh deform detail on the surface, so results depends on quality of the depth map
- normal_loss_weight: Optional. Use to refine the mesh deform detail on the surface
- sdf_regularizer_weight: Helps to remove floaters in areas of the shape that are not supervised by the application objective, such as internal faces when using image supervision only
- remove_floaters_weight: This can be increased if you observe artifacts in flat areas
- cube_stabilizer_weight: This does not have a significant impact during the optimization of a single shape, however it helps to stabilizing training in somecases
<video controls autoplay loop src="https://github.com/MrForExample/ComfyUI-3D-Pack/assets/62230687/166bbc1f-04b7-42c8-87bb-302e3f5aabb2"></video>
-
Instant NGP: nerfacc
- Multi-View images as inputs
- Export to 3D Mesh using marching cubes
-
3D Gaussian Splatting
- Improved Differential Gaussian Rasterization
- Better Compactness-based Densification method from Gsgen,
- Support initialize gaussians from given 3D mesh (Optional)
- Support mini-batch optimazation
- Multi-View images as inputs
- Export to standard 3DGS .ply format supported
-
Gaussian Splatting Orbit Renderer
- Render 3DGS to images sequences or video, given a 3DGS file and camera poses generated by Stack Orbit Camera Poses node
-
Mesh Orbit Renderer
- Render 3D mesh to images sequences or video, given a mesh file and camera poses generated by Stack Orbit Camera Poses node
-
Fitting_Mesh_With_Multiview_Images
- Bake Multi-View images into UVTexture of given 3D mesh using Nvdiffrast, supports:
- Export to .obj, .ply, .glb
-
Save & Load 3D file
- .obj, .ply, .glb for 3D Mesh
- .ply for 3DGS
-
Switch Axis for 3DGS & 3D Mesh
- Since different algorithms likely use different coordinate system, so the ability to re-mapping the axis of coordinate is crucial for passing generated result between differnt nodes.
-
Customizable system config file
- Custom clients IP address
- Add your huggingface user token
Roadmap:
-
[X] Integrate CharacterGen
-
[ ] Improve 3DGS/Nerf to Mesh conversion algorithms:
- Find better methods to converts 3DGS or Points Cloud to Mesh (Normal maps reconstruction maybe?)
-
[ ] Add & Improve a few best MVS algorithms (e.g 2DGS, etc.)
-
[ ] Add camera pose estimation from raw multi-views images
Development
How to Contribute
- Fork the project
- Make Improvements/Add New Features
- Creating a Pull Request to dev branch
Project Structure
-
nodes.py: <br>Contains the interface code for all Comfy3D nodes (i.e. the nodes you can actually seen & use inside ComfyUI), you can add your new nodes here
-
Gen_3D_Modules: <br>A folder that contains the code for all generative models/systems (e.g. multi-view diffusion models, 3D reconstruction models). New 3D generative modules should be added here
-
MVs_Algorithms: <br>A folder that contains the code for all multi-view stereo algorithms, i.e. algorighms (e.g. Gaussian Splatting, NeRF and FlexiCubes) that takes multi-view images and convert it to 3D representation (e.g. Gaussians, MLP or Mesh). New MVS algorithms should be added here
-
web: <br>A folder that contains the files & code (html, js, css) for all browser UI related things (e.g. the html layout, style and the core logics for preview 3D Mesh & Gaussians). New web UI should be added here
-
webserver: <br>A folder that contains the code for communicate with browser, i.e. deal with web client requests (e.g. Sending 3D Mesh to client when requested with certain url routes). New web server related functions should be added here
-
Configs: <br>A folder that contains different config files for different modules, new config should be added here, use a sub folder if there are more than one config to a single module (e.g. Unique3D, CRM)
-
Checkpoints: <br>A folder that contains all the pre-trained model and some of the model architecture config files required by diffusers, New checkpoints if could be downloaded automatically by
Load_Diffusers Pipelinenode, then it should be added here -
install.py: <br>Main install script, will download & install Pre-builds automatically according to your runtime environment, if it couldn't find corresponding Pre-builds, then build script will start automatically, called by ComfyUI-Manager right after it installed the dependencies listed in requirements.txt using pip <br>If the new modules your are trying to add needs some additional packages that cannot be simplly added into requirements.txt and build_config.remote_packages, then you can try to add it by modify this script
-
_Pre_Builds: <br>A folder that contains the files & code for build all required dependencies, if you want to pre-build some additional dependencies, then please check _Pre_Builds/README.md for more informations
Tips
- OpenGL (Three.js, Blender) world & camera coordinate system:
World Camera +y up target | | / | | / |______+x |/______right / / / / / / +z forward z-axis is pointing towards you and is coming out of the screen elevation: in (-90, 90), from +y to +x is (-90, 0) azimuth: in (-180, 180), from +z to +x is (0, 90) - If you encounter OpenGL errors (e.g.,
[F glutil.cpp:338] eglInitialize() failed), then setforce_cuda_rasterizeto true on corresponding node - If after the installation, your ComfyUI gets stuck at starting or running, you can follow the instructions in the following link to solve the problem: Code Hangs Indefinitely When Evaluating Neuron Models on GPU