Nodes Browser
ComfyDeploy: How ComfyUI-bleh works in ComfyUI?
What is ComfyUI-bleh?
Better TAESD previews, BlehHyperTile.
How to install it in ComfyDeploy?
Head over to the machine page
- Click on the "Create a new machine" button
- Select the
Editbuild steps - Add a new step -> Custom Node
- Search for
ComfyUI-blehand select it - Close the build step dialig and then click on the "Save" button to rebuild the machine
BLEH
A ComfyUI nodes collection of utility and model patching functions. Also includes improved previewer that allows previewing batches during generation.
For recent user-visible changes, please see the ChangeLog.
Features
- Better TAESD previews (see below).
- Allow setting seed, timestep range and step interval for HyperTile (look for the
BlehHyperTilenode). - Allow applying Kohya Deep Shrink to multiple blocks, also allow gradually fading out the downscale factor (look for the
BlehDeepShrinknode). - Allow discarding penultimate sigma (look for the
BlehDiscardPenultimateSigmanode). This can be useful if you find certain samplers are ruining your image by spewing a bunch of noise into it at the very end (usually only an issue withdpm2 aor SDE samplers). - Allow more conveniently switching between samplers during sampling (look for the BlehInsaneChainSampler node).
- Apply arbitrary model patches at an interval and/or for a percentage of sampling (look for the BlehModelPatchConditional node).
- Ensure a seed is set even when
add_noiseis turned off in a sampler. Yes, that's right: if you don't haveadd_noiseenabled no seed gets set for samplers likeeuler_aand it's not possible to reproduce generations. (look for the BlehForceSeedSampler node). ForSamplerCustomAdvancedyou can useBlehDisableNoiseto accomplish the same thing. - Allows swapping to a refiner model at a predefined time (look for the BlehRefinerAfter node).
- Allow defining arbitrary model patches (look for the BlehBlockOps node).
- Experimental blockwise CFG type effect (look for the BlehBlockCFG node).
- SageAttention support either globally or as a sampler wrapper. Look for the BlehSageAttentionSampler and
BlehGlobalSageAttentionnodes.
Configuration
Copy either blehconfig.yaml.example or blehconfig.json.example to blehconfig.yaml or blehconfig.json respectively and edit the copy. When loading configuration, the YAML file will be prioritized if it exists and Python has YAML support.
Restart ComfyUI to apply any new changes.
Better TAESD previews
- Supports setting max preview size (ComfyUI default is hardcoded to 512 max).
- Supports showing previews for more than the first latent in the batch.
- Supports throttling previews. Do you really need your expensive TAESD preview to get updated 3 times a second?
Current defaults:
|Key|Default|Description|
|-|-|-|
|enabled|true|Toggles whether enhanced TAESD previews are enabled|
|max_size|768|Max width or height for previews. Note this does not affect TAESD decoding, just the preview image|
|max_width|max_size|Same as max_size except allows setting the width independently. Previews may not work well with non-square max dimensions.|
|max_height|max_size|Same as max_size except allows setting the height independently. Previews may not work well with non-square max dimensions.|
|max_batch|4|Max number of latents in a batch to preview|
|max_batch_cols|2|Max number of columns to use when previewing batches|
|throttle_secs|2|Max frequency to decode the latents for previewing. 0.25 would be every quarter second, 2 would be once every two seconds|
|maxed_batch_step_mode|false|When false, you will see the first max_batch previews, when true you will see previews spread across the batch|
|preview_device|null|null (use the default device) or a string with a PyTorch device name like "cpu", "cuda:0", etc. Can be used to run TAESD previews on CPU or other available devices. Not recommended to change this unless you really need to, using the CPU device may prevent out of memory errors but will likely significantly slow down generation.|
|skip_upscale_layers|0|The TAESD model has three upscale layers, each doubles the size of the result. Skipping some of them will significantly speed up TAESD previews at the cost of smaller preview image results. You can set this to -1 to automatically pop layers until at least one dimension is within the max width/height or -2 to aggressively pop until both dimensions are within the limit.|
|compile_previewer|false|Controls whether the previewer gets compiled with torch.compile. May be a boolean or an object in which case the object will be used as argument to torch.compile. Note: May cause a delay/memory spike on the first preview.|
|oom_fallback|latent2rgb|May be set to none or latent2rgb. Controls what happens if trying to decode the preview runs out of memory.|
|oom_retry|true|If set to false, we will give up and use the oom_fallback behavior after hitting the first OOM. Otherwise, we'll attempt to decode with the normal previewer each time a preview is requested, even if that previously ran out of memory.|
These defaults are conservative. I would recommend setting throttle_secs to something relatively high (like 5-10) especially if you are generating batches at high resolution.
Slightly more detailed explanation for maxed_batch_step_mode: If max previews is set to 3 and the batch size is 15 you will see previews for indexes 0, 5, 10. Or to put it a different way, it steps through the batch by batch_size / max_previews rounded up. This behavior may be useful for previewing generations with a high batch count like when using AnimateDiff.
More detailed explanation for skipping upscale layers: Latents (the thing you're running the TAESD preview on) are 8 times smaller than the image you get decoding by normal VAE or TAESD. The TAESD decoder has three upscale layers, each doubling the size: 1 * 2 * 2 * 2 = 8. So for example if normal decoding would get you a 1280x1280 image, skipping one TAESD upscale layer will get you a 640x640 result, skipping two will get you 320x320 and so on. I did some testing running TAESD decode on CPU for a 1280x1280 image: the base speed is about 1.95 sec base, 1.15 sec with one upscale layer skipped, 0.44 sec with two upscale layers skipped and 0.16 sec with all three upscale layers popped (of course you only get a 160x160 preview at that point). The upshot is if you are using TAESD to preview large images or batches or you want to run TAESD on CPU (normally pretty slow) you would probably benefit from setting skip_upscale_layers to 1 or 2. Also if your max preview size is 768 and you are decoding a 1280x1280 image, it's just going to get scaled down to 768x768 anyway.
Note: Other node packs that patch ComfyUI's previewer behavior may interfere with this feature. One I am aware of is ComfyUI-VideoHelperSuite - if you have displaying animated previews turned on, it will overwrite Bleh's patched previewer. Or possibly, depending on the load order, Bleh will prevent it from working correctly.
BlehModelPatchConditional
Note: Very experimental.
This node takes a default model and a matched model. When the interval or start/end percentage match, the matched model will apply, otherwise the default one will. This can be used to apply something like HyperTile, Self Attention Guidance or other arbitrary model patches conditionally.
The first sampling step that matches the timestep range always applies matched, after that the following behavior applies: If the interval is positive then you just get matched every interval steps. It is also possible to set interval to a negative value, for example -3 would mean out of every three steps, the first two use matched and the third doesn't.
Notes and limitations: Not all types of model modifications/patches can be intercepted with a node like this. You also almost certainly can't use this to mix different models: both inputs should be instances of the same loaded model. It's also probably a bad idea to apply further patches on top of the BlehModelPatchConditional node output: it should most likely be the last thing before a sampler or something that actually uses the model.
BlehHyperTile
Adds the ability to set a seed and timestep range that HyperTile gets applied for. Not well tested, and I just assumed the Inspire version works which may or may not be the case.
It is also possible to set an interval for HyperTile steps, this time it is just normal sampling steps that match the timestep range. The first sampling step that matches the timestep range always applies HyperTile, after that the following behavior applies: If the interval is positive then you just get HyperTile every interval steps. It is also possible to set interval to a negative value, for example -3 would mean out of every three steps, the first two have HyperTile and the third doesn't.
Note: Timesteps start from 999 and count down to 0 and also are not necessarily linear. Figuring out exactly which sampling step a timestep applies to is left as an exercise for you, dear node user. As an example, Karras and exponential samplers essentially rush to low timesteps and spend quite a bit of time there.
HyperTile credits:
The node was originally taken by Comfy from taken from: https://github.com/tfernd/HyperTile/
Then the Inspire node pack took it from the base ComfyUI node: https://github.com/ltdrdata/ComfyUI-Inspire-Pack
Then I took it from the Inspire node pack. The original license was MIT so I assume yoinking it into this repo is probably okay.
BlehDeepShrink
AKA PatchModelAddDownScale AKA Kohya Deep Shrink. Compared to the built-in Deep Shrink node this version has the following differences:
- Instead of choosing a block to apply the downscale effect to, you can enter a comma-separated list of blocks. This may or not actually be useful but it seems like you can get interesting effects applying it to multiple blocks. Try
2,3or1,2,3. - Adds a
start_fadeout_percentinput. When this is less thanend_percentthe downscale will be scaled to end atend_percent. For example, ifdownscale_factor=2.0,start_percent=0.0,end_percent=0.5andstart_fadeout_percent=0.0then at 25% you could expectdownscale_factorto be around1.5. This is because we are deep shrinking between 0 and 50% and we are halfway through the effect range. (downscale_factor=1.0would of course be a no-op and values below 1 don't seem to work.) - Expands the options for upscale and downscale types, you can also turn on antialiasing for
bicubicandbilinearmodes.
Notes: It seems like when shrinking multiple blocks, blocks downstream are also affected. So if you do x2 downscaling on 3 blocks, you are going to be applying x2 * 3 downscaling to the lowest block (and maybe downstream ones?). I am not 100% sure how it works, but the takeway is you want to reduce the downscale amount when you are downscaling multiple blocks. For example, using blocks 2,3,4 and a downscale factor of 2.0 or 2.5 generating at 3072x3072 seems to work pretty well. Another note is schedulers that move at a steady pace seem to produce better results when fading out the deep shrink effect. In other words, exponential or Karras schedulers don't work well (and may produce complete nonsense). ddim_uniform and sgm_uniform seem to work pretty well and normal appears to be decent.
Deep Shrink credits:
Adapted from the ComfyUI source which I presume was adapted from the version Kohya initially published.
BlehInsaneChainSampler
Note: I'd recommend using my Overly Complicated Sampling node pack over this. It generally has better tools for scheduling samplers.
A picture is worth a thousand words, so:
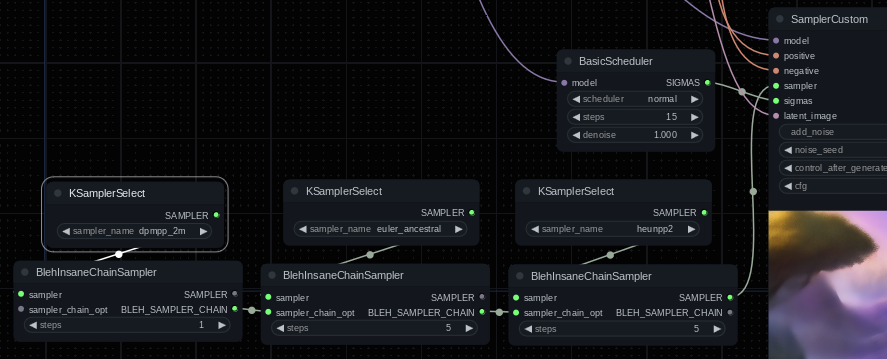
This will use heunpp2 for the first five steps, euler_ancestral for the next five, and dpmpp_2m for however many remain.
This is basically the same as chaining a bunch of samplers together and manually setting the start/end steps.
Note: Even though the dpmpp_2m insane chain sampler node has steps=1 it will run for five steps. This is because the requirement of fifteen total steps must be fulfilled and... you can't really sample stuff without a sampler. Also note progress might be a little weird splitting sampling up like this.
BlehForceSeedSampler
Currently, the way ComfyUI's advanced and custom samplers work is if you turn off add_noise no global RNG seed gets set. Samplers like euler_a use this (SDE samplers use a different RNG method and aren't subject to this issue). Anyway, the upshot is you will get a different generation every time regardless of what the seed is set to. This node simply wraps another sampler and ensures that the seed gets set.
BlehDisableNoise
Basically the same idea as BlehForceSeedSampler, however it is usable with SamplerCustomAdvanced.
BlehPlug
You can connect this node to any input and it will be the same as if the input had no connection. Why is this useful? It's mainly for Use Everywhere — sometimes it's desirable to leave an input unconnected, but if you have Use Everywhere broadcasting an output it can be inconvenient. Just shove a plug in those inputs.
BlehSetSamplerPreset
Allows associating a SAMPLER with a name in list of samplers (bleh_preset_0, etc) so you can use a custom sampler in places that do not allow custom sampling - FaceDetailer for example. You can adjust the number of presets by setting the environment variable COMFYUI_BLEH_SAMPLER_PRESET_COUNT - it defaults to 1 if unset. If set to 0, no sampler presets will be added to the list.
This node needs to run before sampling with the preset begins - it takes a wildcard input with can be used to pass through something like the model or latent to make sure the node runs before sampling. Note: Since the input and outputs are wildcards, ComfyUI's normal type checking does not apply here - be sure you connect the output to something that supports the input type. For example, if you connect a MODEL to any_input, ComfyUI will let you connect that to something expecting LATENT which won't work very well.
It's also possible to override the sigmas used for sampling - possibly to do something like Restart sampling in nodes that don't currently allow you to pass in sigmas. This is an advanced option, if you don't know that you need it then I suggest not connecting anything here. Note: If the sampler is adding noise then you likely will get unexpected results if the two sets of sigmas start at different values. (This could also be considered a feature since it effectively lets you apply a multiplier to the initial noise.)
The dummy_opt input can be attached to anything and isn't used by the node. However, you can connect something like a string or integer and change it to ensure the node runs again and sets your preset. See the note below.
Note: One thing to be aware of is that this node assigns the preset within the ComfyUI server when it runs, so if you are changing and using the same preset ID between samplers, you need to make sure the BlehSetSamplerPreset node runs before the corresponding sampler. For example, suppose you have a workflow that looks like Set Preset 0 -> KSampler1 (with preset 0) -> Set Preset 0 -> KSampler2 (with preset 0). The Set Preset nodes will run before each KSampler as expected the first time you execute the workflow. However, if you go back and change a setting in KSampler1 and run the workflow, this won't cause the first Set Preset node to run again so you'll be sampling with whatever got assigned to the preset with the second Set Preset node. You can change a value connected to the dummy_opt input to force the node to run again.
BlehRefinerAfter
Allows switching to a refiner model at a predefined time. There are three time modes:
timestep: Note that this is not a sampling step but a value between0and999where999is the beginning of sampling and0is the end. It is basically equivalent to the percentage of sampling remaining -999= ~99.9% sampling remaining.percent: Value between0.0and1.0where0.0is the start of sampling and 1.0 is the end. Note that this is not based on sampling steps.sigma: Advanced option. If you don't know what this is you probably don't need to worry about it.
Note: This only patches the unet apply function, most other stuff including conditioning comes from the base model so you likely can only use this to swap between models that are closely related. For example, switching from SD 1.5 to SDXL is not going to work at all.
BlehBlockCFG
Experimental model patch that attempts to guide either cond (positive prompt) or uncond (negative prompt) away from its opposite.
In other words, when applied to cond it will try to push it further away from what uncond is doing and vice versa. Stronger effect when
applied to cond or output blocks. The defaults are reasonable for SD 1.5 (or as reasonable as weird stuff like this can be).
Enter comma separated blocks numbers starting with one of Iinput, Output or Middle like i4,m0,o4. You may also use * rather than a block
number to select all blocks in the category, for example i*, o* matches all input and all output blocks.
The patch can be applied to the same model multiple times.
Is it good, or even doing what I think? Who knows! Both positive and negative scales seem to have positive effect on the generation. Low negative scales applied to cond seem to make the generation bright and colorful.
Note: Probably only works with SD 1.x and SDXL. Middle block patching will probably only work if you have FreeU_Advanced installed.
Note: Doesn't work correctly with Tiled Diffusion when using tile batch sizes over 1.
BlehSageAttentionSampler
Allows using the SageAttention attention optimization as a sampler wrapper. SageAttention 2.0.1 supports head sizes up to 128 and should have some effect for most models. Earlier SageAttention versions had more limited support and, for example, didn't support any of SD1.5's head sizes. You will probably notice the biggest difference for high resolution generations.
If you run into custom nodes that don't seem to be honoring SageAttention (you can verify this with sageattn_verbose: true in the YAML options), feel free to let me know and I can probably add support. At this point the Bleh SageAttention stuff should work for most custom nodes.
Note: Requires manually installing SageAttention into your Python environment. Should work with SageAttention 1.0 and 2.0.x (2.0.x currently requires CUDA 8+). Link: https://github.com/thu-ml/SageAttention
BlehGlobalSageAttention
Enables SageAttention (see description above) globally. Prefer using the sampler wrapper when possible as it has less sharp edges.
Note: This isn't a real model patch. The settings are applied when the node runs, so, for example, if you enable it and then bypass the node that won't actually disable SageAttention. The node needs to actually run each time you want your settings applied.
BlehBlockOps
Very experimental advanced node that allows defining model patches using YAML. This node is still under development and may be changed.
Examples
Just to show what's possible, you can implement model patches like FreeU or Deep Shrink using BlockOps.
FreeU V2
# FreeU V2 b1=1.1, b2=1.2, s1=0.9, s2=0.2
- if:
type: output
stage: 1
ops:
- [slice, 0.75, 1.1, 1, null, true]
- [target_skip, true]
- [ffilter, 0.9, none, 1.0, 1]
- if:
type: output
stage: 2
ops:
- [slice, 0.75, 1.2, 1, null, true]
- [target_skip, true]
- [ffilter, 0.2, none, 1.0, 1]
Kohya Deep Shrink
# Deep Shrink, downscale 2, apply up to 35%.
- if:
type: input_after_skip
block: 3
to_percent: 0.35
ops: [[scale, bicubic, bicubic, 0.5, 0.5, 0]]
- if:
type: output
ops: [[unscale, bicubic, bicubic, 0]]
BlehLatentOps
Basically the same as BlehBlockOps, except the condition type will be latent. Obviously stuff involving steps, percentages, etc do not apply.
This node allows you to apply the blending/filtering/scaling operations to a latent.
BlehLatentScaleBy
Like the builtin LatentScaleBy node, however it allows setting the horizontal and vertical scaling types and scales independently
as well as allowing providing an extended list of scaling options. Can also be useful for testing what different types of scaling or
enhancement effects look like.
BlehLatentBlend
Allows blending latents using any of the blending modes available.
BlehCast
Advanced node: Allows tricking ComfyUI into thinking a value of one type is a different type. This does not actually convert anything, just lets you connect things that otherwise couldn't be connected. In other words, don't do it unless you know the actual object is compatible with the input.
BlehSetSigmas
Advanced sigma manipulation node which can be used to insert sigmas into other sigmas, adjust them, replace them or just manually enter a list of sigmas. Note: Experimental, not well tested.
Scaling Types
- bicubic: Generally the safe option.
- bilinear: Like bicubic but slightly not as good?
- nearest-exact
- area
- bislerp: Interpolates between tensors a and b using normalized linear interpolation.
- colorize: Supposedly transfers color. May or may not work that way.
- hslerp: Hybrid Spherical Linear Interporation, supposedly smooths transitions between orientations and colors.
- bibislerp: Uses bislerp as the slerp function in bislerp. When slerping once just isn't enough.
- cosinterp: Cosine interpolation.
- cuberp: Cubic interpolation.
- inject: Adds the value scaled by the ratio. Probably not the best for scaling.
- lineardodge: Supposedly simulates a brightning effect.
- random: Chooses a random relatively normal scaling function each time. My thought is this will avoid artifacts from a specific scaling type from getting reinforced each step. Generally only useful for Deep Shrink or jankhdiffusion.
- randomaa: Like
random, however it will also choose a random antialias size.
Scaling types like bicubic+something will apply the something enhancement after scaling. See below.
Scaling types that start with rev like revinject reverse the arguments to the scaling function.
For example, inject does a + b * scale, revinject does b + a * scale. When is this desirable?
I really don't know! Just stuff to experiment with. It may or may not be useful. (revcosinterp looks better than cosinterp though.)
Note: Scaling types like random are very experimental and may be modified or removed.
Enhancement Types
- randmultihighlowpass: Randomly uses multihighpass or multilowpass filter. Effect is generally quite strong.
- randhilowpass: Randomly uses a highpass or lowpass filter. When you filter both high and low frequencies you are left with... nothing! The effect is very strong. May not be useful.
- randlowbandpass: Randomly uses a bandpass or lowpass filter.
- randhibandpass: Randomly uses a bandpass or highpass filter.
- renoise1: Adds some gaussian noise. Starts off relatively weak and increases based on sigma.
- renoise2: Adds some guassian noise. Starts relatively strong and decreases based on sigma.
- korniabilateralblur: Applies a bilateral (edge preserving) blur effect.
- korniagaussianblur: Applies a guassian blur effect.
- korniasharpen: Applies a sharpen effect.
- korniaedge: Applies an edge enhancement effect.
- korniarevedge: Applies an edge softening effect - may not work correctly.
- korniarandblursharp: Randomly chooses between blurring and sharpening.
Also may be an item from Filters.
Note: These enhancements are very experimental and may be modified or removed.
Credits
Latent blending and scaling and filter functions based on implementation from https://github.com/WASasquatch/FreeU_Advanced - thanks!