Nodes Browser
ComfyDeploy: How ComfyUI_OmniGen_Wrapper works in ComfyUI?
What is ComfyUI_OmniGen_Wrapper?
ComfyUI custom node of OmniGen project.
How to install it in ComfyDeploy?
Head over to the machine page
- Click on the "Create a new machine" button
- Select the
Editbuild steps - Add a new step -> Custom Node
- Search for
ComfyUI_OmniGen_Wrapperand select it - Close the build step dialig and then click on the "Save" button to rebuild the machine
ComfyUI_OmniGen_Wrapper
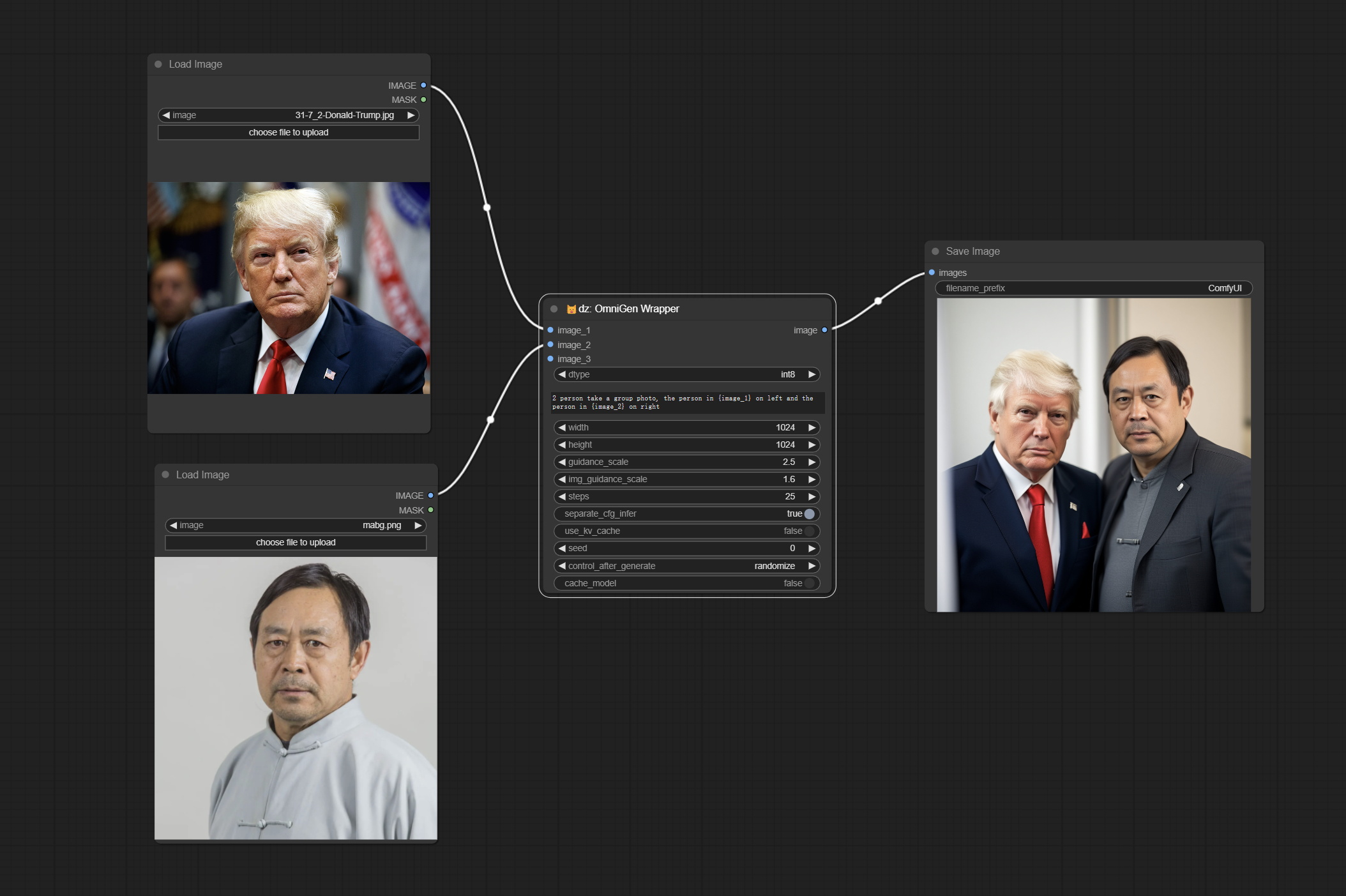
This node is an unofficial wrapper of the OmniGen, running in ComfyUI.
The quantization code is referenced from Manni1000/OmniGen.
Install
Open a terminal window in the ComfyUI/custom_nodes folder and enter the following command:
git clone https://github.com/chflame163/ComfyUI_OmniGen_Wrapper.git
Install dependencies
Run the following command in the Python environment of ComfyUI:
python -s -m pip install -r ComfyUI/custom_nodes/ComfyUI_OmniGen_Wrapper/requirements.txt
Download models
When running the plugin for the first time, the model will be automatically downloaded. If the automatic download fails, you can manually download it. Choose one of the following two download methods:
From Huggingface:
- Download all files from Shitao/OmniGen-v1 and copy to
ComfyUI/models/OmniGen/Shitao/OmniGen-v1folder; - Download
diffusion_pytorch_model.safetensorsandconfig.jsonfrom stabilityai/sdxl-vae, copy the two files toComfyUI/models/OmniGen/Shitao/OmniGen-v1/vaefolder.
Or Download all files from BaiduNetdisk and copy to ComfyUI/models/OmniGen/Shitao/OmniGen-v1 folder.
How to use
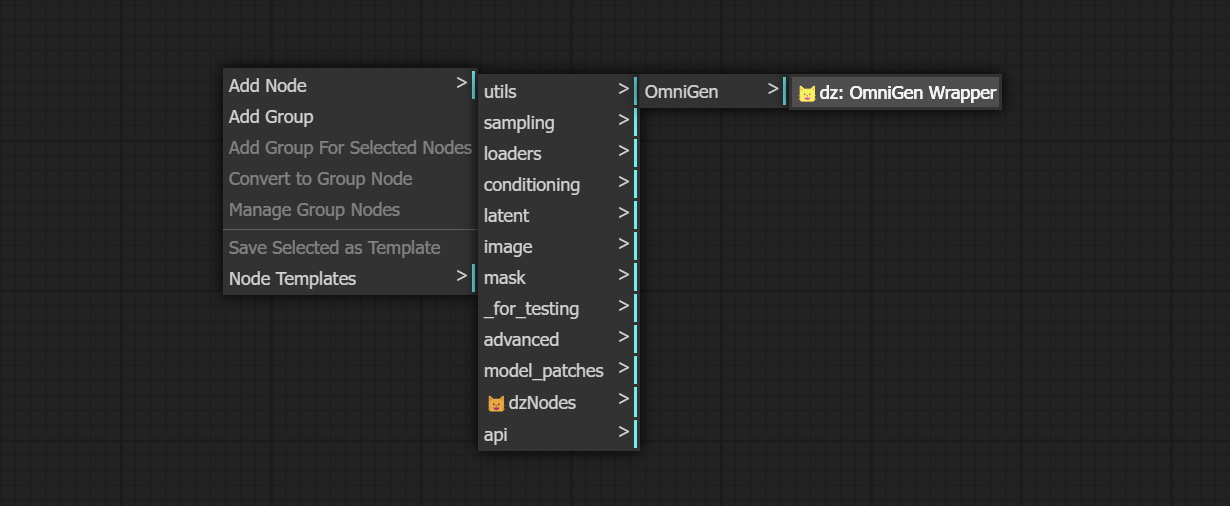
Start ComfyUI, right click on screen to activate the menu, find Add Node - 😺dzNodes - OmniGen Wrapper, the node is here.
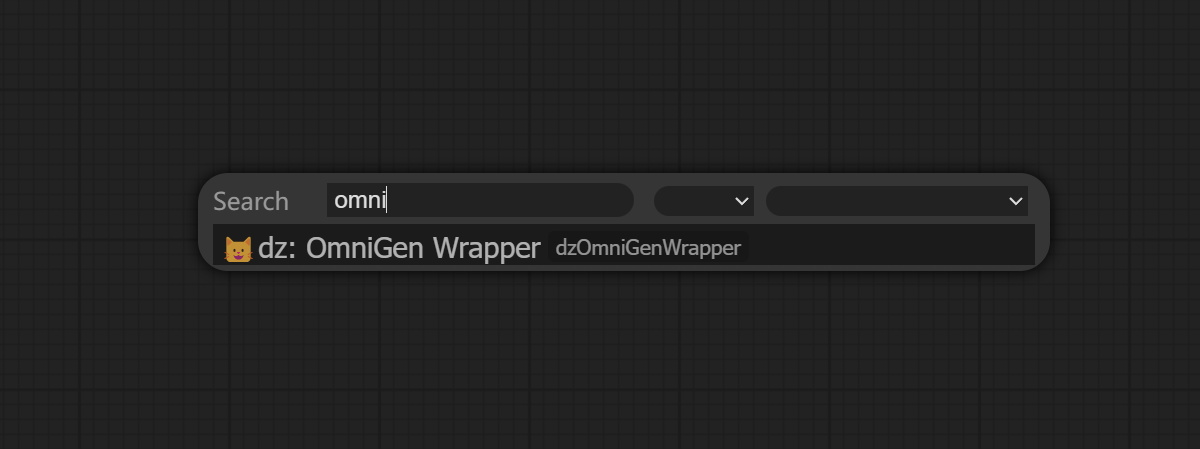
Alternatively, enter OmniGen Wrapper in the node search bar to find the node.
Node Options
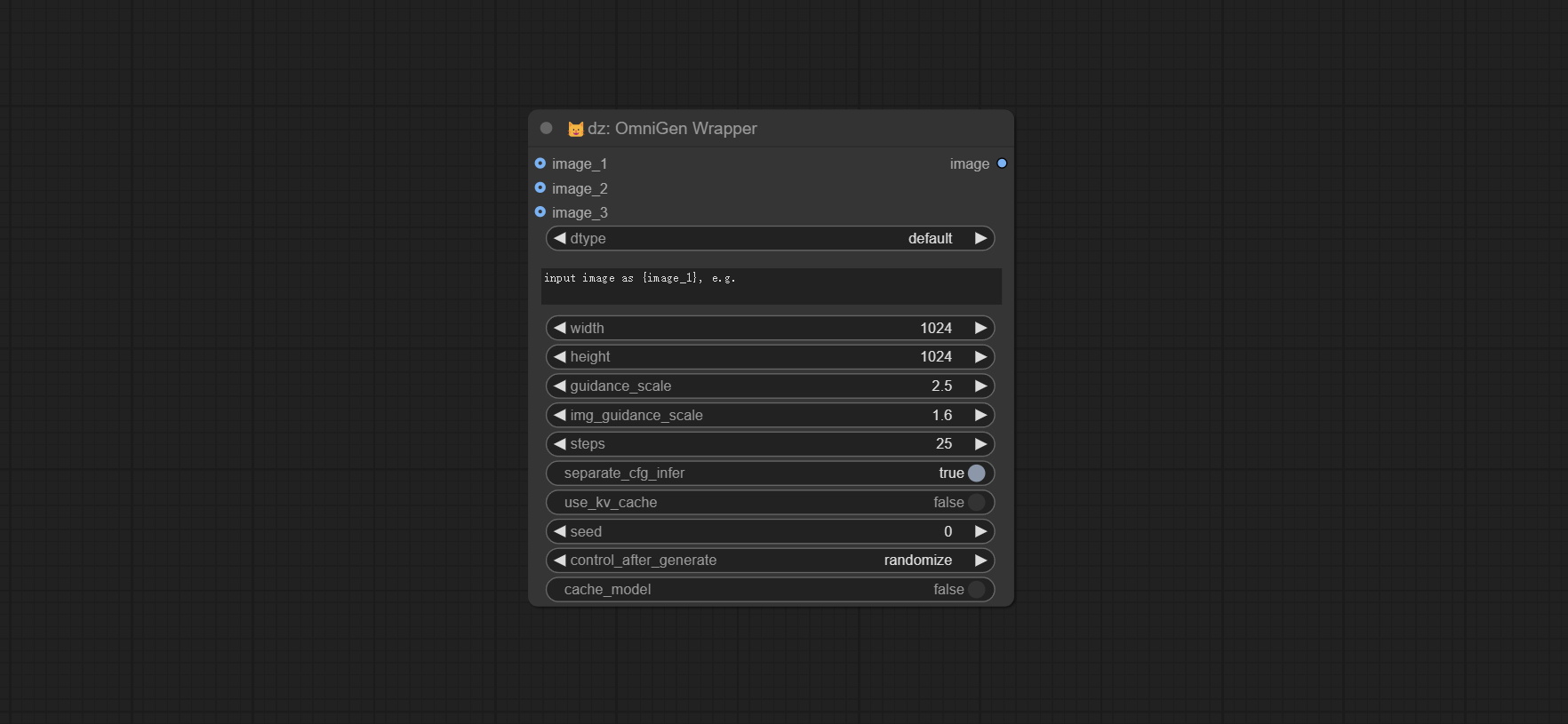
- image_1: Optional input image_1. If input, this image must be described in the prompt and referred to as
{image_1}. - image_2: Optional input image_2. If input, this image must be described in the prompt and referred to as
{image_2}. - image_3: Optional input image_3. If input, this image must be described in the prompt and referred to as
{image_3}. - dtype: Model accuracy, default is the default model accuracy, optional int8. The default precision occupies approximately 12GB of video memory, while int8 occupies approximately 7GB of video memory.
- prompt: The prompt or prompts to guide the image generation. If have image input, use the placeholder
{image_1},{image_2},{image_3}to refer to it. - width: The height in pixels of the generated image. The number must be a multiple of 16.
- height: The width in pixels of the generated image. The number must be a multiple of 16.
- guidance_scale: A higher value will make the generated results of the model more biased towards the condition, but may sacrifice the diversity and degrees of freedom of the image.
- image_guidance_scale: The guidance scale of image.
- steps: The number of denoising steps. More denoising steps usually lead to a higher quality image at the expense of slower inference.
- separate_cfg_infer: Perform inference on images with different guidance separately; this can save memory when generating images of large size at the expense of slower inference.
- use_kv_cache: Enable kv cache to speed up the inference
- seed: A random seed for generating output.
- control_after_generate: Seed value change option every time it runs.
- cache_model: When set to True, the model is cached and does not need to be loaded again during the next run.
Star
statement
This project follows the MIT license, Some of its functional code comes from other open-source projects. Thanks to the original author. If used for commercial purposes, please refer to the original project license to authorization agreement.