Nodes Browser
ComfyDeploy: How comfyui_LLM_party works in ComfyUI?
What is comfyui_LLM_party?
A set of block-based LLM agent node libraries designed for ComfyUI.This project aims to develop a complete set of nodes for LLM workflow construction based on comfyui. It allows users to quickly and conveniently build their own LLM workflows and easily integrate them into their existing SD workflows.
How to install it in ComfyDeploy?
Head over to the machine page
- Click on the "Create a new machine" button
- Select the
Editbuild steps - Add a new step -> Custom Node
- Search for
comfyui_LLM_partyand select it - Close the build step dialig and then click on the "Save" button to rebuild the machine

Comfyui_llm_party aims to develop a complete set of nodes for LLM workflow construction based on comfyui as the front end. It allows users to quickly and conveniently build their own LLM workflows and easily integrate them into their existing image workflows.
Effect display
https://github.com/user-attachments/assets/945493c0-92b3-4244-ba8f-0c4b2ad4eba6
Project Overview
ComfyUI LLM Party, from the most basic LLM multi-tool call, role setting to quickly build your own exclusive AI assistant, to the industry-specific word vector RAG and GraphRAG to localize the management of the industry knowledge base; from a single agent pipeline, to the construction of complex agent-agent radial interaction mode and ring interaction mode; from the access to their own social APP (QQ, Feishu, Discord) required by individual users, to the one-stop LLM + TTS + ComfyUI workflow required by streaming media workers; from the simple start of the first LLM application required by ordinary students, to the various parameter debugging interfaces commonly used by scientific researchers, model adaptation. All of this, you can find the answer in ComfyUI LLM Party.
Quick Start
- If you have never used ComfyUI and encounter some dependency issues while installing the LLM party in ComfyUI, please click here to download the Windows portable package that includes the LLM party. Please note that this portable package contains only the party and manager plugins, and is exclusively compatible with the Windows operating system.(If you need to install LLM party into an existing comfyui, this step can be skipped.)
- Drag the following workflows into your comfyui, then use comfyui-Manager to install the missing nodes.
- Use API to call LLM: start_with_LLM_api
- Using aisuite to call LLM: start_with_aisuite
- Manage local LLM with ollama: start_with_Ollama
- Use local LLM in distributed format: start_with_LLM_local
- Use local LLM in GGUF format: start_with_LLM_GGUF
- Use local VLM in distributed format: start_with_VLM_local (testing, currently only supports Llama-3.2-Vision-Instruct)
- Use local VLM in GGUF format: start_with_VLM_GGUF
- If you are using API, fill in your
base_url(it can be a relay API, make sure it ends with/v1/), for example:https://api.openai.com/v1/andapi_keyin the API LLM loader node. - If you are using ollama, turn on the
is_ollamaoption in the API LLM loader node, no need to fill inbase_urlandapi_key. - If you are using a local model, fill in your model path in the local model loader node, for example:
E:\model\Llama-3.2-1B-Instruct. You can also fill in the Huggingface model repo id in the local model loader node, for example:lllyasviel/omost-llama-3-8b-4bits. - Due to the high usage threshold of this project, even if you choose the quick start, I hope you can patiently read through the project homepage.
Latest update
- A new browser tool node has been developed based on browser-use, which allows the LLM to automatically perform the browser tasks you publish.
- The nodes for loading files, loading folders, loading web content, and all word embedding-related nodes have been upgraded. Now, the file content you load will always include the file name and paragraph index. The loading folder node can filter the files you wish to load through
related_characters. - A local model tool for speech-to-text has been added, which is theoretically compatible with all ASR models on HF. For example: openai/whisper-small, nyrahealth/CrisperWhisper, and so forth.
- Added ASR and TTS nodes for fish audio, please refer to the API documentation of fish audio for usage instructions.
- Added the aisuite loader node, which is compatible with all APIs that aisuite can accommodate, including: ["openai", "anthropic", "aws", "azure", "vertex", "huggingface"]. Example workflow: start_with_aisuite.
- A new category has been added: memory nodes, which can be utilized to manage your LLM conversation history. Currently, memory nodes support three modes for managing your conversation history: local JSON files, Redis, and SQL. By decoupling the LLM's conversation history from the LLM itself, you can employ word embedding models to compress and organize your conversation history, thus saving tokens and context windows for the LLM. Example workflow: External Memory.
- A local file reading tool has been added. In comparison to the previous local file control tool in ComfyUI LLM Mafia, this tool can only read files or the file tree within a specific folder, thus ensuring greater security.
- Forked chatgpt-on-wechat, created a new repository party-on-wechat. The installation and usage methods are the same as the original project, no configuration is required, just start the party's FastAPI. By default, it calls the wx_api workflow and supports image output. It will be updated gradually to ensure a smooth experience of party on WeChat.
- Added an In-Context-LoRA mask node, used for generating consistent In-Context-LoRA prompts.
- We have added a frontend component with features laid out from left to right as follows:
- Saves your API key and Base URL to the
config.inifile. When you use thefix nodefunction on the API LLM loader node, it will automatically read the updated API key and Base URL from theconfig.inifile. - Starts a FastAPI service that can be used to call your ComfyUI workflow. If you run it directly, you get an OpenAI interface at
http://127.0.0.1:8817/v1/. You need to connect the start and end of your workflow to the 'Start Workflow' and 'End Workflow', then save in API format to theworkflow_apifolder. Then, in any frontend that can call the OpenAI interface, inputmodel name=<your workflow name without the .json extension>,Base URL=http://127.0.0.1:8817/v1/, and the API key can be filled with any value. - Starts a Streamlit application; the workflow saving process is as above. You can select your saved workflow in the 'Settings' of the Streamlit app and interact with your workflow agent in the 'Chat'.
- 'About Us', which introduces this project.
- Saves your API key and Base URL to the
- The automatic model name list node has been removed and replaced with a simple API LLM loader node, which automatically retrieves your model name list from the configuration in your config.ini file. You just need to select a name to load the model. Additionally, the simple LLM loader, simple LLM-GGUF loader, simple VLM loader, simple VLM-GGUF loader, and simple LLM lora loader nodes have been updated. They all automatically read the model paths from the model folder within the party folder, making it easier for everyone to load various local models.
- LLMs can now dynamically load lora like SD and FLUX. You can chain multiple loras to load more loras on the same LLM. Example workflow: start_with_LLM_LORA.
- Added the searxng tool, which can aggregate searches across the entire web. Perplexica also relies on this aggregation search tool, so you can set up a Perplexica at your party. You can deploy the searxng/searxng public image in Docker, then start it using
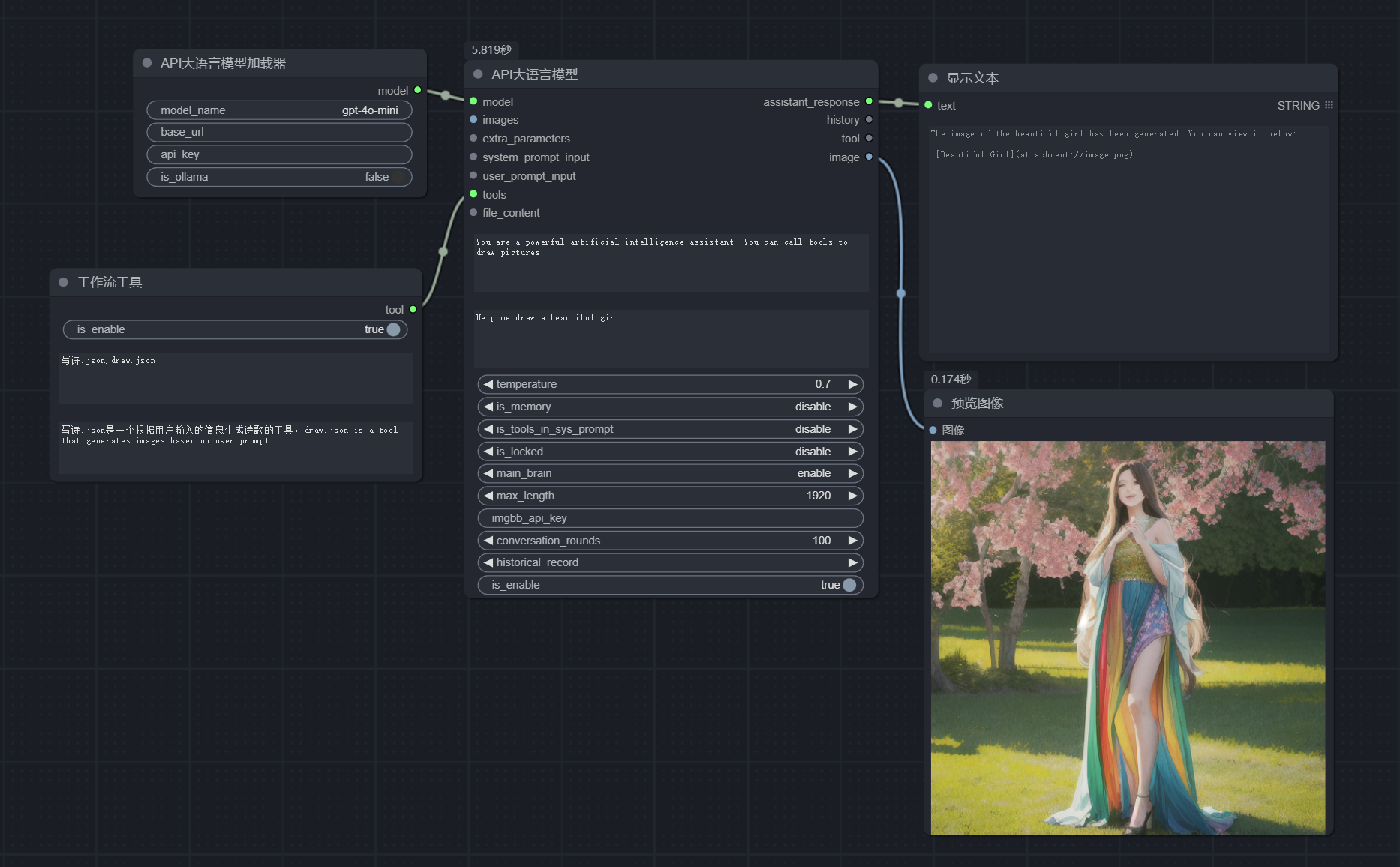
docker run -d -p 8080:8080 searxng/searxng, and access it usinghttp://localhost:8080. You can fill in this URLhttp://localhost:8080in the party's searxng tool, and then you can use searxng as a tool for LLM. - Major Update!!! Now you can encapsulate any ComfyUI workflow into an LLM tool node. You can have your LLM control multiple ComfyUI workflows simultaneously. When you want it to complete some tasks, it can choose the appropriate ComfyUI workflow based on your prompt, complete your task, and return the result to you. Example workflow: comfyui_workflows_tool. The specific steps are as follows:
- First, connect the text input interface of the workflow you want to encapsulate as a tool to the "user_prompt" output of the "Start Workflow" node. This is where the prompt passed in when the LLM calls the tool.
- Connect the positions where you want to output text and images to the corresponding input positions of the "End Workflow" node.
- Save this workflow as an API (you need to enable developer mode in the settings to see this button).
- Save this workflow to the workflow_api folder of this project.
- Restart ComfyUI and create a simple LLM workflow, such as: start_with_LLM_api.
- Add a "Workflow Tool" node to this LLM node and connect it to the tool input of the LLM node.
- In the "Workflow Tool" node, write the name of the workflow file you want to call in the first input box, for example: draw.json. You can write multiple workflow file names. In the second input box, write the function of each workflow so that the LLM understands how to use these workflows.
- Run it to see the LLM call your encapsulated workflow and return the result to you. If the return is an image, connect the "Preview Image" node to the image output of the LLM node to view the generated image. Note! This method calls a new ComfyUI on your 8190 port, please do not occupy this port. A new terminal will be opened on Windows and Mac systems, please do not close it. The Linux system uses the screen process to achieve this, when you do not need to use it, close this screen process, otherwise, it will always occupy your port.
User Guide
-
For the instructions for using the node, please refer to: how to use nodes
-
If there are any issues with the plugin or you have other questions, feel free to join the QQ group: 931057213 | discord:discord.
-
Please refer to the workflow tutorial: Workflow Tutorial, thanks to HuangYuChuh for your contribution!
-
Advanced workflow gameplay account:openart
-
More workflows please refer to the workflow folder.
{kind=link}
Vedio tutorial
<a href="https://space.bilibili.com/26978344"> <img src="img/B.png" width="100" height="100" style="border-radius: 80%; overflow: hidden;" alt="octocat"/> </a> <a href="https://www.youtube.com/@comfyui-LLM-party"> <img src="img/YT.png" width="100" height="100" style="border-radius: 80%; overflow: hidden;" alt="octocat"/> </a>Model support
- Support all API calls in openai format(Combined with oneapi can call almost all LLM APIs, also supports all transit APIs), base_url selection reference config.ini.example, which has been tested so far:
- openai (Perfectly compatible with all OpenAI models, including the 4o and o1 series!)
- ollama (Recommended! If you are calling locally, it is highly recommended to use the ollama method to host your local model!)
- Azure OpenAI
- llama.cpp (Recommended! If you want to use the local gguf format model, you can use the llama.cpp project's API to access this project!)
- Grok
- Tongyi Qianwen /qwen
- zhipu qingyan/glm
- deepseek
- kimi/moonshot
- doubao
- spark
- Gemini(The original Gemini API LLM loader node has been deprecated in the new version. Please use the LLM API loader node, with the base_url selected as: https://generativelanguage.googleapis.com/v1beta/)
- Support for all API calls compatible with aisuite:
- Compatible with most local models in the transformer library (the model type on the local LLM model chain node has been changed to LLM, VLM-GGUF, and LLM-GGUF, corresponding to directly loading LLM models, loading VLM models, and loading GGUF format LLM models). If your VLM or GGUF format LLM model reports an error, please download the latest version of llama-cpp-python from llama-cpp-python. Currently tested models include:
- ClosedCharacter/Peach-9B-8k-Roleplay(Recommended! Role-playing model)
- lllyasviel/omost-llama-3-8b-4bits(Recommended! Rich prompt model)
- meta-llama/llama-2-7b-chat-hf
- Qwen/Qwen2-7B-Instruct
- openbmb/MiniCPM-V-2_6-gguf
- lmstudio-community/Meta-Llama-3.1-8B-Instruct-GGUF
- meta-llama/Llama-3.2-11B-Vision-Instruct
- Model download
- Quark cloud address
- Baidu cloud address, extraction code: qyhu
Download
- You can configure the language in
config.ini, currently only Chinese (zh_CN) and English (en_US), the default is your system language. - Install using one of the following methods:
Method 1:
- Search for comfyui_LLM_party in the comfyui manager and install it with one click.
- Restart comfyui.
Method 2:
- Navigate to the
custom_nodessubfolder under the ComfyUI root folder. - Clone this repository with
git clone https://github.com/heshengtao/comfyui_LLM_party.git.
Method 3:
- Click
CODEin the upper right corner. - Click
download zip. - Unzip the downloaded package into the
custom_nodessubfolder under the ComfyUI root folder.
Environment Deployment
- Navigate to the
comfyui_LLM_partyproject folder. - Enter
pip install -r requirements.txtin the terminal to deploy the third-party libraries required by the project into the comfyui environment. Please ensure you are installing within the comfyui environment and pay attention to anypiperrors in the terminal. - If you are using the comfyui launcher, you need to enter
path_in_launcher_configuration\python_embeded\python.exe -m pip install -r requirements.txtin the terminal to install. Thepython_embededfolder is usually at the same level as yourComfyUIfolder. - If you have some environment configuration problems, you can try to use the dependencies in
requirements_fixed.txt.
Configuration
APIKEY can be configured using one of the following methods
Method 1:
- Open the
config.inifile in the project folder of thecomfyui_LLM_party. - Enter your openai_api_key, base_url in
config.ini. - If you are using an ollama model, fill in
http://127.0.0.1:11434/v1/inbase_url,ollamainopenai_api_key, and your model name inmodel_name, for example:llama3. - If you want to use Google search or Bing search tools, enter your
google_api_key,cse_idorbing_api_keyinconfig.ini. - If you want to use image input LLM, it is recommended to use image bed imgbb and enter your imgbb_api in
config.ini. - Each model can be configured separately in the
config.inifile, which can be filled in by referring to theconfig.ini.examplefile. After you configure it, just entermodel_nameon the node.
Method 2:
- Open the comfyui interface.
- Create a Large Language Model (LLM) node and enter your openai_api_key and base_url directly in the node.
- If you use the ollama model, use LLM_api node, fill in
http://127.0.0.1:11434/v1/inbase_urlnode, fill inollamainapi_key, and fill in your model name inmodel_name, for example:llama3. - If you want to use image input LLM, it is recommended to use graph bed imgbb and enter your
imgbb_api_keyon the node.
Changelog
- You can right-click in the comfyui interface, select
llmfrom the context menu, and you will find the nodes for this project. how to use nodes - Supports API integration or local large model integration. Modular implementation for tool invocation.When entering the base_url, please use a URL that ends with
/v1/.You can use ollama to manage your model. Then, enterhttp://127.0.0.1:11434/v1/for the base_url,ollamafor the api_key, and your model name for the model_name, such as: llama3.
- API access sample workflow: start_with_LLM_api
- Local model access sample workflow: start_with_LLM_local
- ollama access sample workflow: ollama
- Local knowledge base integration with RAG support.sample workflow: Knowledge Base RAG Search
- Ability to invoke code interpreters.
- Enables online queries, including Google search support.sample workflow: movie query workflow
- Implement conditional statements within ComfyUI to categorize user queries and provide targeted responses.sample workflow: intelligent customer service
- Supports looping links for large models, allowing two large models to engage in debates.sample workflow: Tram Challenge Debate
- Attach any persona mask, customize prompt templates.
- Supports various tool invocations, including weather lookup, time lookup, knowledge base, code execution, web search, and single-page search.
- Use LLM as a tool node.sample workflow: LLM Matryoshka dolls
- Rapidly develop your own web applications using API + Streamlit.
- Added a dangerous omnipotent interpreter node that allows the large model to perform any task.
- It is recommended to use the
show_textnode under thefunctionsubmenu of the right-click menu as the display output for the LLM node. - Supported the visual features of GPT-4O!sample workflow:GPT-4o
- A new workflow intermediary has been added, which allows your workflow to call other workflows!sample workflow:Invoke another workflow
- Adapted to all models with an interface similar to OpenAI, such as: Tongyi Qianwen/QWEN, Zhigu Qingyan/GLM, DeepSeek, Kimi/Moonshot. Please fill in the base_url, api_key, and model_name of these models into the LLM node to call them.
- Added an LVM loader, now you can call the LVM model locally, support lava-llama-3-8b-v1_1-gguf model, other LVM models should theoretically run if they are GGUF format.The example workflow can be found here: start_with_LVM.json.
- I wrote a
fastapi.pyfile, and if you run it directly, you’ll get an OpenAI interface onhttp://127.0.0.1:8817/v1/. Any application that can call GPT can now invoke your comfyui workflow! I will create a tutorial to demonstrate the details on how to do this. - I’ve separated the LLM loader and the LLM chain, dividing the model loading and model configuration. This allows for sharing models across different LLM nodes!
- macOS and mps devices are now supported! Thanks to bigcat88 for their contribution!
- You can build your own interactive novel game, and go to different endings according to the user's choice! Example workflow reference: interactive_novel
- Adapted to OpenAI's whisper and tts functions, voice input and output can be realized. Example workflow reference: voice_input&voice_output
- Compatible with Omost!!! Please download omost-llama-3-8b-4bits to experience it now! Sample workflow reference: start_with_OMOST
- Added LLM tools to send messages to WeCom, DingTalk, and Feishu, as well as external functions to call.
- Added a new text iterator, which can output only part of the characters at a time. It is safe to split the text according to Carriage Return and chunk size, and will not be divided from the middle of the text. chunk_overlap refers to how many characters the divided text overlaps. In this way, you can enter super long text in batches, as long as you don't have a brain to click, or open the loop in comfyui to execute, it can be automatically executed. Remember to turn on the is_locked property, which can automatically lock the workflow at the end of the input and will not continue to execute. Example workflow: text iteration input
- Added the model name attribute to the local LLM loader, local llava loader. If it is empty, it will be loaded using various local paths in the node. If it is not empty, it will be loaded using the path parameters you fill in yourself in
config.ini. If it is not empty and not inconfig.ini, it will be downloaded from huggingface or loaded from the model save directory of huggingface. If you want to download from huggingface, please fill in the format of for example:THUDM/glm-4-9b-chat.Attention! Models loaded in this way must be adapted to the transformer library. - Added JSON file parsing node and JSON value node, which allows you to get the value of a key from a file or text. Thanks to guobalove for your contribution!
- Improved the code of tool call. Now LLM without tool call function can also open is_tools_in_sys_prompt attribute (local LLM does not need to be opened by default, automatic adaptation). After opening, the tool information will be added to the system prompt word, so that LLM can call the tool.Related papers on implementation principles: Achieving Tool Calling Functionality in LLMs Using Only Prompt Engineering Without Fine-Tuning
- A new custom_tool folder is created to store the code of the custom tool. You can refer to the code in the custom_tool folder, put the code of the custom tool into the custom_tool folder, and you can call the custom tool in LLM.
- Added Knowledge Graph tool, so that LLM and Knowledge Graph can interact perfectly. LLM can modify Knowledge Graph according to your input, and can reason on Knowledge Graph to get the answers you need. Example workflow reference: graphRAG_neo4j
- Added personality AI function, 0 code to develop your own girlfriend AI or boyfriend AI, unlimited dialogue, permanent memory, stable personality. Example workflow reference: Mylover Personality AI
- You can use this LLM tool maker to automatically generate LLM tools, save the tool code you generated as a python file, and then copy the code to the custom_tool folder, and then you create a new node. Example workflow: LLM tool generator.
- It supports duckduckgo search, but it has significant limitations. It seems that only English keywords can be entered, and multiple concepts cannot appear in keywords. The advantage is that there are no APIkey restrictions.
- It supports the function of calling multiple knowledge bases separately, and it is possible to specify which knowledge base is used to answer questions in the prompt word. Example workflow: multiple knowledge bases are called separately.
- Support LLM input extra parameters, including advanced parameters such as json out. Example workflow: LLM input extra parameters.Separate prompt words with json_out.
- Added the function of connecting the agent to discord. (still testing)
- Added the function of connecting the agent to Feishu, thank you very much guobalove for your contribution! Refer to the workflow Feishu robot.
- Added universal API call node and a large number of auxiliary nodes for constructing the request body and grabbing the information in the response.
- Added empty model node, you can uninstall LLM from video memory at any location!
- The chatTTS node has been added, thank you very much for the contribution of guobalove!
model_pathparameter can be empty! It is recommended to useHFmode to load the model, the model will be automatically downloaded from hugging face, no need to download manually; if usinglocalloading, please put the model'sassetandconfigfolders in the root directory. Baidu cloud address, extraction code: qyhu; if usingcustommode to load, please put the model'sassetandconfigfolders undermodel_path. - Updated a series of conversion nodes: markdown to HTML, svg to image, HTML to image, mermaid to image, markdown to Excel.
- Compatible with the llama3.2 vision model, supports multi-turn dialogue, visual functions. Model address: meta-llama/Llama-3.2-11B-Vision-Instruct. Example workflow: llama3.2_vision.
- Adapted GOT-OCR2, supports formatted output results, supports fine text recognition using position boxes and colors. Model address: GOT-OCR2. Example workflow converts a screenshot of a webpage into HTML code and then opens the browser to display this webpage: img2web.
- The local LLM loader nodes have been significantly adjusted, so you no longer need to choose the model type yourself. The llava loader node and GGUF loader node have been re-added. The model type on the local LLM model chain node has been changed to LLM, VLM-GGUF, and LLM-GGUF, corresponding to directly loading LLM models, loading VLM models, and loading GGUF format LLM models. VLM models and GGUF format LLM models are now supported again. Local calls can now be compatible with more models! Example workflows: LLM_local, llava, GGUF
- Added EasyOCR node for recognizing text and positions in images. It can generate corresponding masks and return a JSON string for LLM to view. There are standard and premium versions available for everyone to choose from!
- In the comfyui LLM party, the strawberry system of the chatgpt-o1 series model was reproduced, referring to the prompts of Llamaberry. Example workflow: Strawberry system compared to o1.
- A new GPT-sovits node has been added, allowing you to call the GPT-sovits model to convert text into speech based on your reference audio. You can also fill in the path of your fine-tuned model (if not filled, the base model will be used for inference) to get any desired voice. To use it, you need to download the GPT-sovits project and the corresponding base model locally, then start the API service with
runtime\python.exe api_v2.pyin the GPT-sovits project folder. Additionally, the chatTTS node has been moved to comfyui LLM mafia. The reason is that chatTTS has many dependencies, and its license on PyPi is CC BY-NC 4.0, which is a non-commercial license. Even though the chatTTS GitHub project is under the AGPL license, we moved the chatTTS node to comfyui LLM mafia to avoid unnecessary trouble. We hope everyone understands! - Now supports OpenAI’s latest model, the o1 series!
- Added a local file control tool that allows the LLM to control files in your specified folder, such as reading, writing, appending, deleting, renaming, moving, and copying files.Due to the potential danger of this node, it is included in comfyui LLM mafia.
- New SQL tools allow LLM to query SQL databases.
- Updated the multilingual version of the README. Workflow for translating the README document: translate_readme
- Updated 4 iterator nodes (text iterator, picture iterator, excel iterator, json iterator). The iterator modes are: sequential, random, and infinite. The order will be output in sequence until the index limit is exceeded, the process will be automatically aborted, and the index value will be reset to 0. Random will choose a random index output, and infinite will loop output.
- Added Gemini API loader node, now compatible with Gemini official API!Since Gemini generates an error with a return code of 500 if the returned parameter contains Chinese characters during the tool call, some tool nodes are unavailable.example workflow:start_with_gemini
- Added lore book node, you can insert your background settings when talking to LLM, example workflow: lorebook
- Added FLUX prompt word generator mask node, which can generate Hearthstone cards, Game King cards, posters, comics and other styles of prompt words, which can make the FLUX model straight out. Reference workflow: FLUX prompt word
Next Steps Plan:
- More model adaptations;
- More ways to build agents;
- More automation features;
- More knowledge base management features;
- More tools, more personas.
Disclaimer:
This open-source project and its contents (hereinafter referred to as "Project") are provided for reference purposes only and do not imply any form of warranty, either expressed or implied. The contributors of the Project shall not be held responsible for the completeness, accuracy, reliability, or suitability of the Project. Any reliance you place on the Project is strictly at your own risk. In no event shall the contributors of the Project be liable for any indirect, special, or consequential damages or any damages whatsoever resulting from the use of the Project.
Special thanks:
<a href="https://github.com/bigcat88"> <img src="https://avatars.githubusercontent.com/u/13381981?v=4" width="50" height="50" style="border-radius: 50%; overflow: hidden;" alt="octocat"/> </a> <a href="https://github.com/guobalove"> <img src="https://avatars.githubusercontent.com/u/171540731?v=4" width="50" height="50" style="border-radius: 50%; overflow: hidden;" alt="octocat"/> </a> <a href="https://github.com/HuangYuChuh"> <img src="https://avatars.githubusercontent.com/u/167663109?v=4" width="50" height="50" style="border-radius: 50%; overflow: hidden;" alt="octocat"/> </a> <a href="https://github.com/SpenserCai"> <img src="https://avatars.githubusercontent.com/u/25168945?v=4" width="50" height="50" style="border-radius: 50%; overflow: hidden;" alt="octocat"/> </a>loan list
Some of the nodes in this project have borrowed from the following projects. Thank you for your contributions to the open-source community!
Support:
Join the community
If there is a problem with the plugin or you have any other questions, please join our community.
- discord:discord link
- QQ group:
931057213
- WeChat group:
Choo-Yong(enter the group after adding the small assistant WeChat)
Follow us
- If you want to continue to pay attention to the latest features of this project, please follow the Bilibili account: Party host BB machine
- The OpenArt account is continuously updated with the most useful party workflows:openart
Donation support
If my work has brought value to your day, consider fueling it with a coffee! Your support not only energizes the project but also warms the heart of the creator. ☕💖 Every cup makes a difference!
<div style="display:flex; justify-content:space-between;"> <img src="img/zhifubao.jpg" style="width: 48%;" /> <img src="img/wechat.jpg" style="width: 48%;" /> </div>