Nodes Browser
ComfyDeploy: How Diffusers-in-ComfyUI works in ComfyUI?
What is Diffusers-in-ComfyUI?
A collection of ComfyUI custom nodes that allow to use most Diffusers pipelines and components in Comfy(Txt2Img, Img2Img, Inpainting, LoRAS, B-LoRAS, ControlNet...)
How to install it in ComfyDeploy?
Head over to the machine page
- Click on the "Create a new machine" button
- Select the
Editbuild steps - Add a new step -> Custom Node
- Search for
Diffusers-in-ComfyUIand select it - Close the build step dialig and then click on the "Save" button to rebuild the machine
Diffusers-in-ComfyUI
This is a custom node allowing the use of the diffusers pipeline into ComfyUI.
This work is greatly inspired by this repository. I decided to recode it from scratch mainly for learning purposes, as well as because at first I only needed a portion of the code. I thank them for this opportunity to learn!
Installation
From Comfy Registry
This node has been added to Comfy Registry (a big thank you to the team for letting me in!). You can install it using Comfy-CLI:
comfy node registry-install diffusers-in-comfyui
From ComfyUI Manager
I was allowed to add this node to ComfyUI Manager's list of custom nodes (thank you Itdrdata!). So once you have launched Comfy UI, go into the UI Manager and search through the available custom nodes for "Diffusers in Comfy UI", and install it.
From scratch
If you want to do everything from scratch and don't even have Comfy UI install, here's what to do. You can follow these steps in Windows, WSL or Linux.
-
Create a conda environment with Python 3.9
-
Activate your environment
-
Then clone ComfyUI repository
-
Follow ComfyUI installation instructions
-
Clone this repo into ComfyUI/custom-nodes and "cd" into it
-
Install this repo's requirelments
-
Launch ComfyUI
-
You should find the nodes under "Diffusers-in-Comfy"!
Nodes
Pipeline nodes
Under "Diffusers-in-Comfy/Pipelines", you will find one node per Diffuser pipeline. Text2ImgStableDiffusionPipeline, Img2ImgStableDiffusionPipeline, and InpaintingStableDiffusionPipeline. Inside each one, you can precise :
- Whether you want to use SDXL.
- Whether you want to use a VAE (write the Hugging Face path to your VAE, for example : "stabilityai/sd-vae-ft-mse")
- Whether you want to use a ControlNet (write the Hugging Face path to your Controlnet model, for example : "XLabs-AI/flux-controlnet-canny")
- Whether you want to activate low VRAM options to avoid low GPU memory issues (this will notably send your pipeline to CPU and activate xformers memory efficient attention)
Inference nodes
Similarly as for pipelines, under "Diffusers-in-Comfy/Inference", you will find one node per type of inference pipeline you want to use : GenerateTxt2Image, GenerateInpaintImage, or GenerateImg2Image. The three of them have common options you can tweak:
- Which controlnet image to use
- Which controlnet scale
- Seed
- Positive prompt
- Negative prompt
- Inference steps
- Width
- Height
- Guidance scale
Then you have specific inputs per node.
GenerateInpaintImage : In this node, you must write the paths to an input image and an input mask for inpainting. Be careful to delete all quotes.
GenerateImg2Image : In this node, you must write the path to an input image to use as a prompt. Be careful to delete all quotes in the path.
Some visual examples of the entire workflows
Txt2Image Workflow:
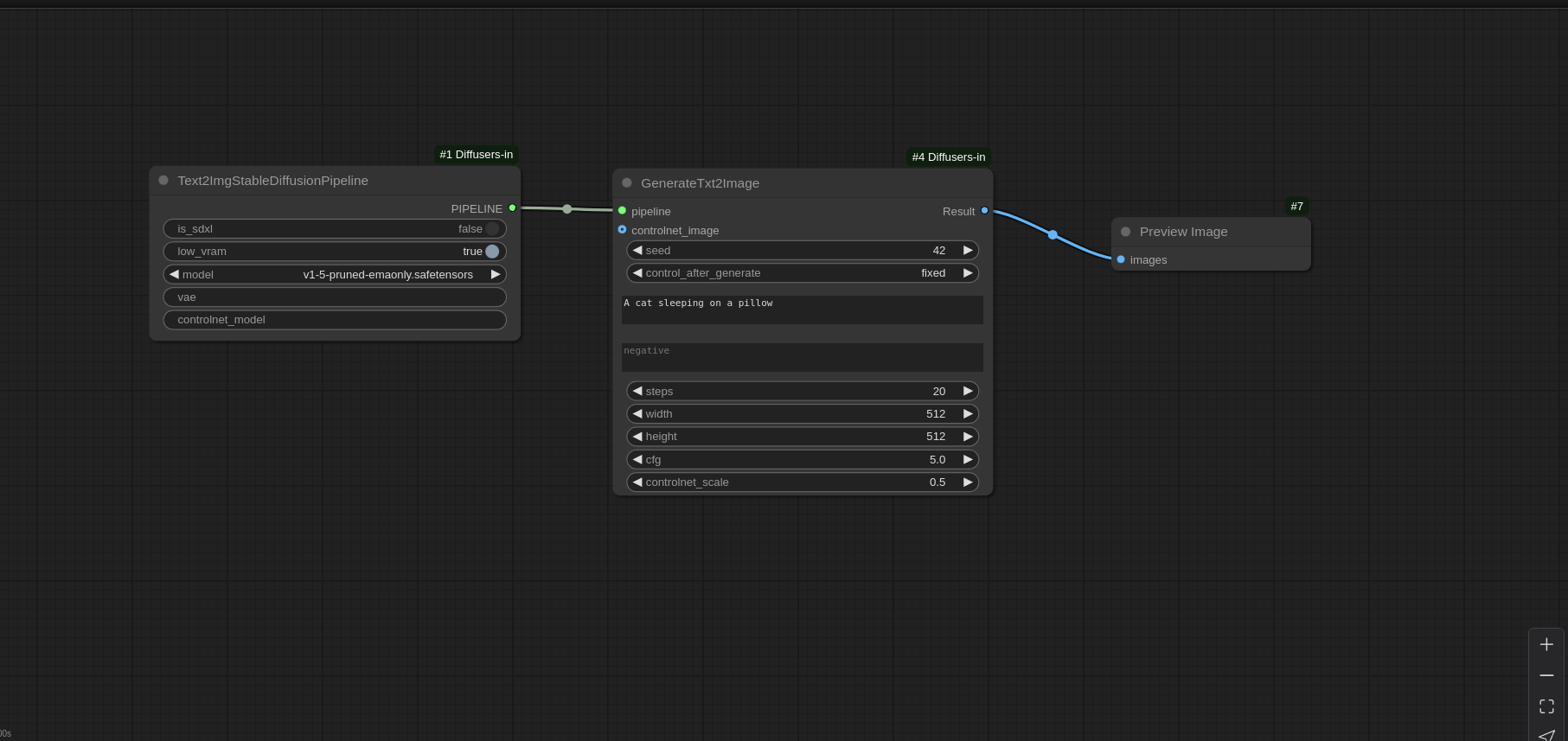
Inpainting Workflow:
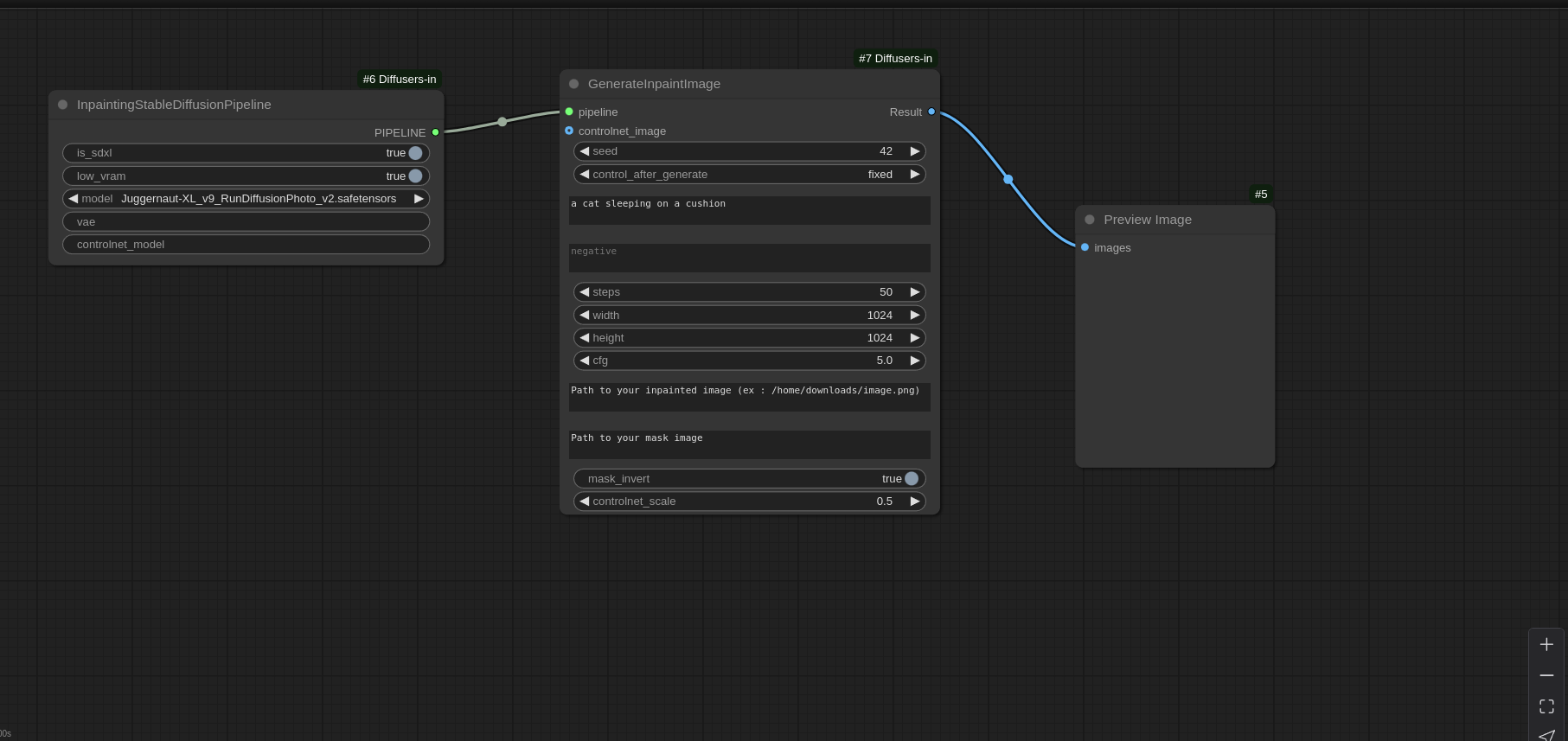
Img2Img Workflow:
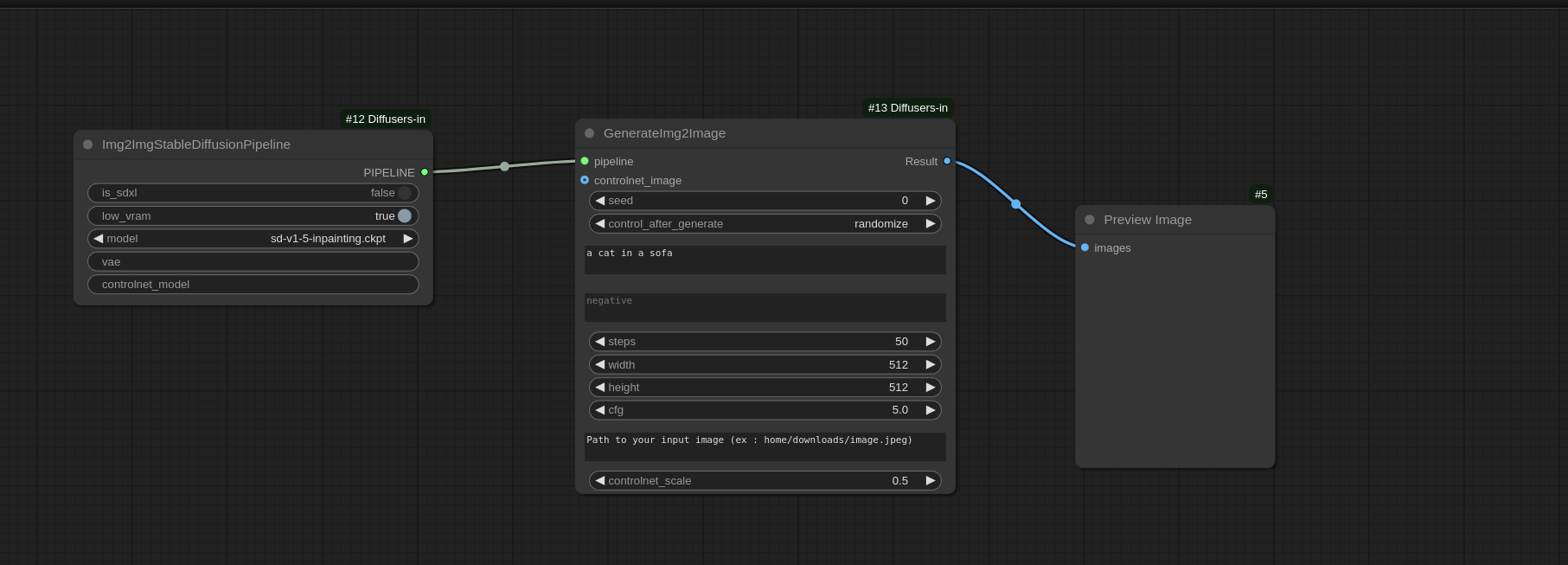
Utils nodes
Under "Diffusers-in-Comfy/Utils", you will find nodes that will allow you to make different operations, such as processing images. For now, only one is available : Make Canny. It takes in an image, transforms it into a canny, and then you can connect the output canny to the "controlnet_image" input of one of the Inference nodes. You also have a second output "Preview" that you can connect to Comfy UI's "Preview Image" to see how your canny looks.
Component nodes
Under "Diffusers-in-Comfy/Components", you will find Diffusers components and adapters that you can load into the Unet. For now, two are available.
LoraLoader : This node allows you to load a LoRA into the UNET and define its weight. Don't forget to write the triggerword into the prompt of the Inference node.
Example of LoRA workflow
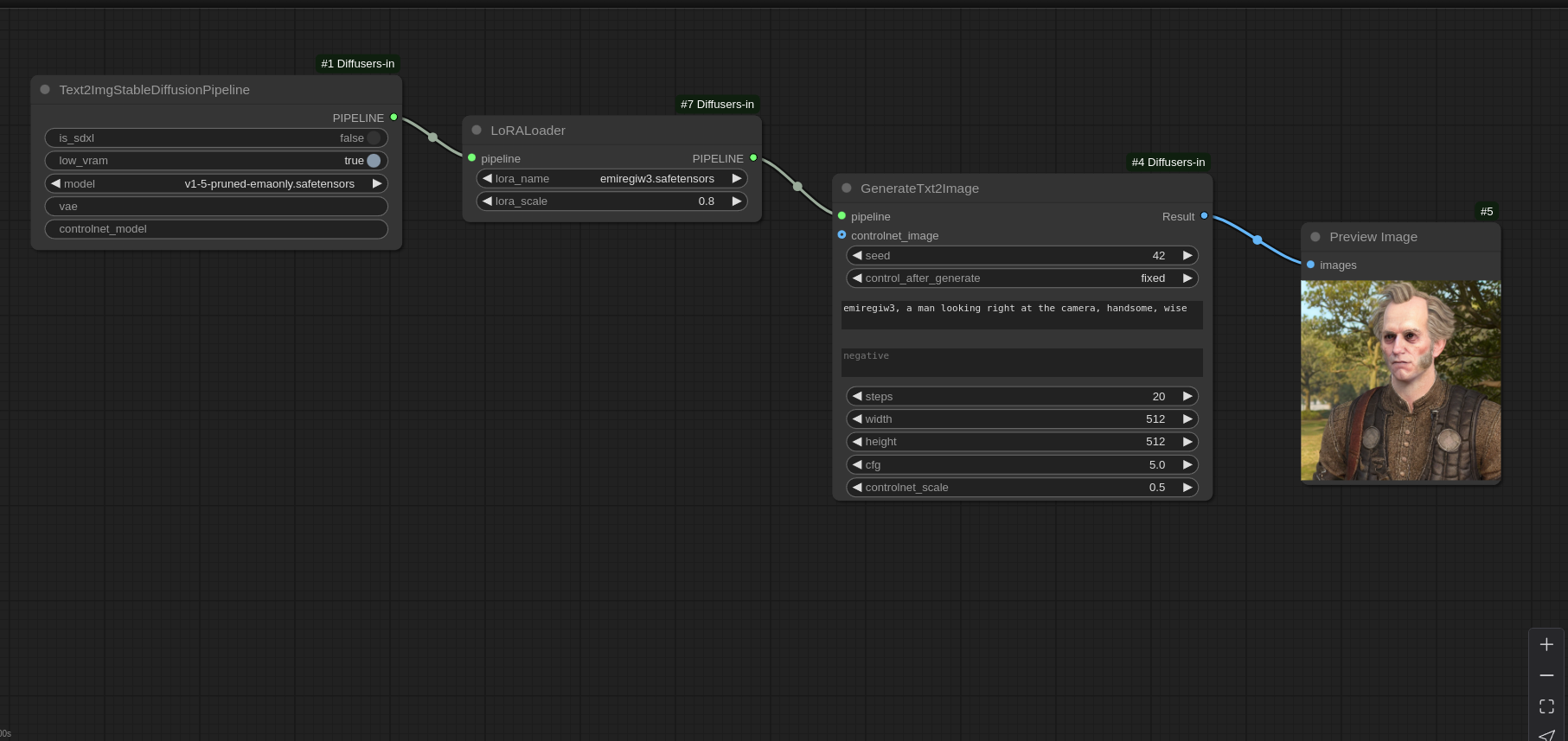
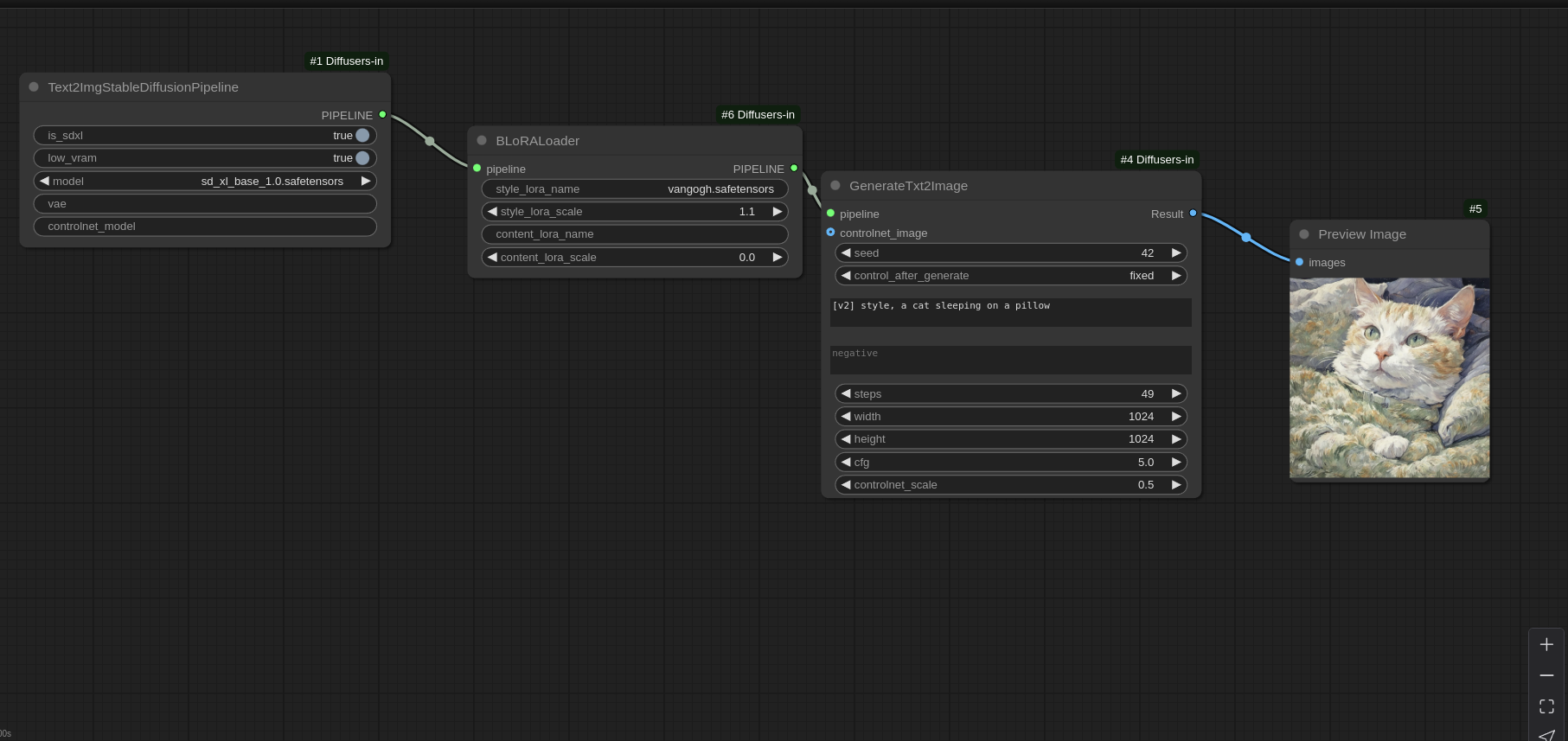
Blora : This node is the reason why I originally created this project. It implements a technique that allows for separating an image into its style and content. It acts as a LoRA but works a bit differently (it updates only two blocks of the Unet). Here's the original repo. Keep in mind that although a B-LoRA works well with a ControlNet, it cannot be used with a classic LoRA. Indeed, the classic LoRA will completely dilute the B-LoRA, supplanting it into the Unet. Also, B-LoRAS work only with SDXL models, so make sure you load a SDXL Pipeline and put the is_sdxl flag of the Pipeline node to "True"!
To load your B-LoRA:
- Put it inside the "lora" folder of your ComfyUI installation
- Inside the node, in style_lora_name and/or content_lora_scale, write the name + extension of your B-LoRA (ex: vangogh.safetensors).
Example of B-LoRA workflow
To do
There are quite a few things I'd like to develop further, so here's a very basic roadmap
- Implement support for IPAdapters
- I don't really like that you have to choose whether your loaded model is SDXL or not. Ideally, I'd like the algo to piggyback on ComfyAPI to determine the architecture automatically.
- I'd like to give the possibility to either load a model locally, or remotely, by writing the path and then maybe add an option to specify whether it's a URL or a local path. Yet this potentially complicates the detection of the architecture, I need to dig deeper into Comfy API to pull this out.
- I'd like the user to be able to browse to the images they want to use, and not have to write the path. For now, I used the path because it allowed me to avoid dealing with Comfy's internal way of processing and handling images.
- A small but important QOL improvement : in all paths written in the inputs, detect and delete quotes
- Implement automatic fetching of the B-LoRAs in the "lora" subfolder, instead oh having to write the name + extension (for example "vangogh.safetensors")
- Test more research papers and implement them as new nodes 😊